Dr. Karl Schmitz
Künstliche Intelligenz- Stand 2026
 Diese Dokument ist ein sehr gründliches Arbeitspapier und richtet sich an alle, die im Detail verstehen wollen, was passiert, wenn man einem Chatbot eine Frage stellt.
Diese Dokument ist ein sehr gründliches Arbeitspapier und richtet sich an alle, die im Detail verstehen wollen, was passiert, wenn man einem Chatbot eine Frage stellt.
Was sich seit der Geburt der Chatbots geändert hat
 Die ersten Chatbots (2022) waren noch recht bescheiden. Sie konnten nicht auf Daten zugreifen, die nach dem Tag des letzten Trainings ihres Sprachmodells lagen. Das hat sich seit 2023 gründlich geändert. Sie können jetzt im Internet suchen, in andere Programme eingebaut werden und auf Wissens-Datenbanken zugreifen.
Die ersten Chatbots (2022) waren noch recht bescheiden. Sie konnten nicht auf Daten zugreifen, die nach dem Tag des letzten Trainings ihres Sprachmodells lagen. Das hat sich seit 2023 gründlich geändert. Sie können jetzt im Internet suchen, in andere Programme eingebaut werden und auf Wissens-Datenbanken zugreifen.
Die oft selbstherrlich auftretenden US-amerikanischen Hersteller mussten einen gehörigen Schreck wegstecken, als Anfang 2025 Chinas DeepSeek ihnen klar machte, dass sich mit deutlich weniger Trainingsaufwand und anderen Verarbeitungsmethoden nicht nur vergleichbare, sondern teils sogar bessere Leistungen erzielen ließen. Seitdem haben sich Techniken wie das Reasoning, das Aufteilen komplexerer Aufgaben in Teilaufgaben, auch Mixture of Expert genannt, auf breiter Front durchgesetzt.
Eine Retrieval Augmented Generation (RAG) genannte Technik erlaubt es inzwischen, Chatbots so einzurichten, dass sie neben ihrem eigenen Sprachmodell auch auf Datenbestände zugreifen können, die ein Unternehmen (oder eine andere Institution) zusätzlich aufbereitet hat (Details siehe Kleine Chatbots mit Insiderwissen).
Damit man besser verstehen kann, welche Chancen, aber auch welche Risiken mit der KI-Technik verbunden sind, nehmen wir jetzt Schritt für Schritt unter die Lupe, was mit der Eingabe einer Benutzerin oder eines Benutzers in den Systemen genau geschieht und vor allem, wie die Antwort der Systeme zustande kommt.
Suche nach externen Informationen
Wie oben bereits erwähnt, endet das interne „Wissen“ eines Chatbots und seinem Sprachmodell mit dem Datum seines letzten Trainings. In einer Zeit mit hohem Aktualitätsanspruch ist das ein absolutes NoGo. Den Chatbots musste also beigebracht werden, dieses Defizit durch eine Suche im Internet auszugleichen.
Chatbots starten diese Internet-Suche nicht automatisch in jedem Fall, sondern klären erst, ob dies notwendig ist. Anhand heuristischer Regeln schätzt das System, ob die gewünschte Antwort in den Daten des Modellwissens gefunden werden kann. Eine Internetsuche wird zum Beispiel immer dann bemüht, wenn in der Benutzeranfrage ein aktueller Zeit- oder Aktualitätsbezug erkennbar ist.
Die gefundenen Ergebnisse werden dann zusammengefasst, von Widersprüchen befreit und sprachlich aufbereitet. Dies erfolgt nach den im Training gelernten Regeln. Die Hersteller betonen, laufend an der Zuverlässigkeit der Ergebnisse zu arbeiten. Inwieweit ihnen das gelingt, konkurriert zunehmend mit ihren kommerziellen Interessen und hängt von der sich verändernden Qualität der zugänglichen Daten ab.
Viele Chatbots erlauben ihren Benutzern, zwischen verschiedenen Modellen zu wählen und insbesondere die Ausführlichkeit der gewünschten Ergebnisse festzulegen. Seit 2024 spielt dabei auch das Bezahlmodell eine Rolle.
Erweiterte Kontentfenster
Die ersten Chatbots hatten jede Anfrage einzeln für sich behandelt und konnten nicht auf vorherige Fragen und Antworten aufbauen. Das hat sich ebenfalls geändert. Bei jeder Anfrage greift der Chatbot auf sein sogenanntes Kontextfenster zu.
Das Kontextfenster besteht aus
- der Eingabe der Benutzerin oder des Benutzers, dem sogenannten Prompt,
- den vorangegangenen Abfragen und den Antworten des Chatbots (wobei je nach Modell ein unterschiedlich großer maximaler Speicherbereich zur Verfügung steht),
- vom Hersteller festgelegten systeminternen Anweisungen und
- eventuell zusätzlichen Informationen wie hochgeladene Dateien oder Texte.
Dieser komplette Inhalt wird für die Anfrage an den Chatbot verwendet und in sog. Token zerlegt; das sind kurze Wörter, Wortteile und auch Satz- und Trennzeichen. Der komplette Kontextfenster-Inhalt wird in eine lineare Reihe gepackt, die neuesten Token am Ende der Kette:
System-Token | frühere User-Token | frühere Antwort-Token | aktuelle User-Token
Google war die erste Firma, die erklärte, das Kontextfenster auf über zwei Millionen Wörter zu erweitern, andere Hersteller sind schnell gefolgt. (Beschreibung zeigen).
Für die Kontextfenster-Verarbeitung hat Google seine Titans-Architektur entwickelt. Eine Größe von Millionen Token verkraftet zurzeit kein noch so großes Sprachmodell. Google will das Problem mit einer Surprise-Metrik lösen, in Form eines speziellen neuronalen Netzes, mit dem der Benutzer-Input bearbeitet wird, bevor er das eigentliche Sprachmodell erreicht. Diese Technik checkt, ob Textpassagen im Vergleich zum restlichen Text des Inputs große Abweichungen aufweisen, woraus das System dann schließt, dass die Überraschungen klein sind, also nicht viel Neues darstellen. Die Passagen werden dann stark komprimiert, in der Erwartung, dass für das angestrebte Ergebnis keine wichtigen Informationen verloren gehen.
Die komplette Input-Sequenz trifft nun auf das Sprachmodell des Chatbots, sein sogenanntes Large Language Model (LLM). Bevor wir sehen, wie es weiter geht, müssen wir uns noch einmal etwas mit dem Sprachmodell selbst beschäftigen.
Das Sprachmodell
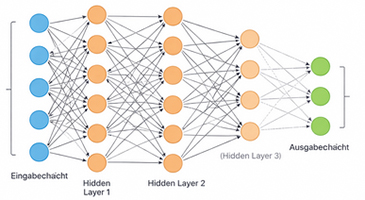 Die heute verwendeten Modelle sind nach dem Transformer-Prinzip gebaut und bedienen sich sogenannter Neuronaler Netzwerke mit einer Eingabeschicht, vielen internen Schichten, den sogenannten hidden layers, und einer Ausgabeschicht. Die internen Schichten haben alle die gleiche Dimension entsprechend der Anzahl ihrer Neuronen. Eine typische Größe für kleine Modelle sind 512 bis 2048, am verbreitetsten für mittelgroße Modelle 4096 und für die leistungsstärksten Spitzenmodelle 8192 oder mehr Dimensionen.
Die heute verwendeten Modelle sind nach dem Transformer-Prinzip gebaut und bedienen sich sogenannter Neuronaler Netzwerke mit einer Eingabeschicht, vielen internen Schichten, den sogenannten hidden layers, und einer Ausgabeschicht. Die internen Schichten haben alle die gleiche Dimension entsprechend der Anzahl ihrer Neuronen. Eine typische Größe für kleine Modelle sind 512 bis 2048, am verbreitetsten für mittelgroße Modelle 4096 und für die leistungsstärksten Spitzenmodelle 8192 oder mehr Dimensionen.
Bei Neuronalen Netzen denkt man oft in Analogie zu unserem Gehirn an Neurone. Die Künstliche Intelligenz hatte ja unter anderem den Anspruch, das nachzubauen, was in unserem Gehirn passiert. Deshalb wurden die einzelnen Elemente eines solchen Netzes oft als Neurone bezeichnet. Das Reden von Künstlichen Neuronen darf man allerdings nicht zu wörtlich nehmen. In Wirklichkeit handelt es sich nur um eine Software-Simulation. Ein künstliches Neuron ist softwaretechnisch eine Rechenvorschrift, die als Teil einer vektorisierten Matrixoperation Eingabewerte verarbeitet und deren Ergebnis als Bestandteil eines neuen Vektors in die nächste Rechenschicht weitergegeben wird. Es gibt also keine Software-Objekte, die Eingaben empfangen und Ergebnisse verschicken. Technisch werden alle sogenannten Neurone einer Schicht gleichzeitig per Matrix-Operation berechnet.
Die Sprachmodelle verfügen über ein Vokabular, über dessen Größe die Entwickler entscheiden. Dieses Vokabular besteht nicht aus Wörtern, sondern aus Token. Das sind kurze Wörter, Wortbestandteile aller Art, Satz- und Sonderzeichen und ein paar vom System gesetzte Zeichen wie EOS (Textende). Lange und zusammengesetzte Wörter sind nicht im Vokabular, sondern sie werden bei Bedarf aus den bereits vorhandenen Token des Vokabulars erzeugt.
Für die Erzeugung des Vokabulars gibt es verschiedene Verfahren (Byte Pair Encoding, Unigram Language Model oder Einsatz eines Byte-basierten Tokenizers). Sie suchen in sehr großen Datenmengen nach häufig vorkommenden Zeichenkombinationen. Man gibt eine gewünschte Grenze vor, z.B. 50.000 Token. Dann startet das Verfahren mit Kombinationen aus zwei Zeichen, erhöht diese Anzahl iterativ immer weiter und sucht nach den häufigsten Vorkommen in der gesamten Datenmenge bis die vorgegebene Grenze erreicht ist.
Der Trick, mit Token statt mit Wörtern zu arbeiten, ist wichtig für einen ökonomischen Betrieb des Modells. Wörter entstehen für die Sprachmodelle nur aus der Kombination von Token. Natürlich gibt es auch ein paar Glückspilze wie einsilbige Wörter, für die Wort und Token gleich sind. Die deutsche Sprache ist ein Paradefall für lange und manchmal komplizierte Wörter. Nehmen wir z.B. das Wort Datenschutzgrundverordnung. Daraus werden die Token daten - schutz - grund - verordnung, wobei verordnung nochmals in ver und ordnung aufgespalten werden kann. Auch Satzzeichen und Sonderzeichen wie Absatzenden werden als Token dargestellt. Man kann sich kaum vorstellen, wie viele unterschiedliche Wörter aus 50.000 Token gebildet werden können.
Wer es genauer wissen will, kann das leicht berechnen: Wenn n die Anzahl der Token ist, aus denen ein Wort besteht, dann berechnet sich die Anzahl A der möglichen Wörter mit n Token bei einem Vokabular mit V Token nach der Formel A = Vn. Das sind bei einem Vokabular von 50.000 Token 1014 oder 125 Billionen mögliche Wörter allein aus drei Token.
Selbst die leistungsfähigsten Sprachmodelle haben nur ein Vokabular von 50.000 bis 100.000 Token und sind in der Regel für viele Sprachen nutzbar. Die Datenauswahl für das Training richtet sich nach der Anzahl der unterstützten Sprachen.
Die Sprachmodelle benutzen für alle von ihnen unterstützte Sprachen nur das eine gemeinsame Vokabular. Dies hat auch den Vorteil, jederzeit zwischen Sprachen hin- und herschalten zu können. Reduziert man die Größe des Vokabulars, so riskiert man, dass sich sprachliche Feinheiten nicht mehr darstellen lassen.
Allzu hohe Tokenzahlen haben deutliche Nachteile: Relevante Informationen gehen in viel Kontext leichter unter, der Speicherbedarf steigt rapide und die Antwortzeiten gehen hoch. Es gilt also, ein Optimum für die Größe des Vokabulars zu finden. Für Chatbots mit einem spezifischen Einsatzgebiet (vgl. Kleine Chatbots mit Insiderwissen) kann man durchaus Sprachmodelle mit geringerem Vokabular verwenden.
Nach dem Training des Modells ist das Vokabular fix. Es ändert sich nicht mehr während des gesamten Betriebs.
Das Embedding
Wenn das gesamte Kontextfenster „tokenisiert“ ist, trifft es auf die Eingabeschicht des Sprachmodells, auch Embedding-Schicht genannt.
Das „Gedächtnis“ des Sprachmodells
Wir müssen uns leider nochmals mit dem „Innenleben“ des Sprachmodells befassen. Es „versteht“ rein gar nichts und kann nur rechnen. Deshalb muss es sich mit den Krücken der Mathematik behelfen. Zu seinem Inventar gehört, dass es eine Liste angelegt hat, die für jedes Token des Vokabulars eine ID und den dazu gehörenden Text enthält, die sogenannte Vocab-Tabelle. Sie wird später noch oft gebraucht und deshalb dauerhaft im Speicher des Rechners gehalten. Die Token der kompletten Benutzereingabe bekommen jetzt jedes eine Zahl aus der Vocab-Tabelle verpasst.
Für den Umgang mit den nun in Zahlen verwandelten Token ist die Vektorrechnung sehr hilfreich. Wir können uns einen Vektor als einen Pfeil vorstellen, der auf irgendeinen Punkt im Raum zeigt. Der von einem Sprachmodell benutzte Raum ist etwas komplizierter als der natürliche Raum, in dem wir leben. Er wird oft Semantischer Raum genannt, semantisch deshalb, weil das Modell die Bedeutung seines Inputs irgendwie abbilden will. Leider ist Sprache sehr komplex, und das bedeutet für das Modell, dass wir mit den uns bekannten drei Dimensionen Länge, Breite und Höhe nicht auskommen.
Das Sprachmodell verwendet deshalb einen hochdimensionalen Vektorraum. Viele leistungsfähige Modelle protzen mit der Zahl ihrer Dimensionen. Wie schon erwähnt, sind 4096 eine gängige Zahl. Das heißt, der Vektorraum des Modells hat dann 4096 Dimensionen, zugegeben etwas jenseits unserer normalen Vorstellung, aber kein Problem für die Mathematik. Sie bildet alle ihre Vektoren einfach in einer Matrix ab. Das stellen wir uns am besten als eine große Tabelle vor, in der jeder Vektor eine Zeile und jede Dimension eine Spalte (oder umgekehrt) ist. Dieses mathematische Ungeheuer nennt sich Token-Embedding-Matrix.
Die Größe dieser Tabelle lässt sich nach der Formel Vokabulargröße x Embedding-Dimension berechnen, für einen Chatbot wie ChatGPT oder Gemini sind das rund 50000 x 4096 = 204.800.000 Werte. Diese Tabelle wird immer im Hauptspeicher des Computers für einen schnellen direkten Zugriff gehalten, denn später muss für jedes einzelne Token der Benutzereingabe in dieser Tabelle nachgesehen werden. Der technische Fortschritt hat uns beschert, dass immer längere Inputs von den Systemen bearbeitet werden können. Und das hat seinen Preis: immer leistungsfähigere Rechner und immer mehr Energieverbrauch werden nötig.
Stellt man die Vektoren durch Pfeile in ihrem semantischen Raum dar, so haben Pfeile, die nahe beieinander liegen, ähnliche Bedeutungen, und zwar umso ähnlicher, je näher sie sich sind. Das Sprachmodell weiß nicht wirklich etwas über den Inhalt der Bedeutungen, sondern hat lediglich Kenntnis über die Beziehung der Token-Vektoren untereinander. Bedeutungen werden also durch Beziehungen erklärt (ausführlicher dargestellt in dem Dokument Verstehen und Bedeutung). Es verhält sich nicht anders, wie in einem klassischen Dictionary, in dem ebenfalls die Bedeutung eines Wortes mit anderen Wörtern erklärt wird (Beispiel siehe Verstehen und Bedeutung).
Die Dimensions-Werte in der Token-Embedding-Matrix sind die im Training des Sprachmodells gelernten Parameter, oft auch als Verbindungsgewichte bezeichnet. Sie sagen nichts über die Bedeutung des Tokens, sondern nur - in zigtausendfacher Ausfertigung - etwas über mögliche Beziehungen der Token zueinander. Wenn Sie das verstehen wollen, dann versuchen Sie, sich vorzustellen, was der Token für die Vorsilbe ver mit dem Token für den Artikel das zu tun hat, betrachtet aus ein paar Tausend verschiedenen Blickwinkeln. In dem schönen Vektorraum liegt das, was viel miteinander zu tun hat, nah beieinander und was überhaupt nicht zusammenpasst, ganz weit voneinander weg.
Der Bedeutungsvektor eines Token ist nur ein mathematisches Objekt. Und das hat den Vorteil, dass man damit rechnen kann.
Das „Ohr“ des Spachmodells
Kehren wir zurück zur Frage, was mit dem Input einer Benutzerin oder eines Benutzers geschieht, also was das Sprachmodell zu hören bekommt, wenn man etwas von ihm will.
Erster Schritt ist, wie bereits erwähnt, die Tokenisierung: Der Inhalt des gesamten Kontentfensters, also der komplette Input wird in Wortstücke zerhackt. Diese Token-Sequenz trifft nun auf die erste Schicht des Sprachmodells, die Embedding-Schicht mit der Token-Embedding-Tabelle für das Vokabular des Modells.
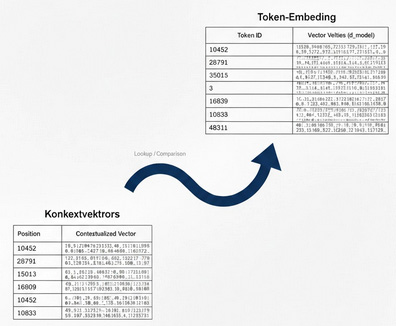
LookUp
Zweiter Schritt ist das Embedding-Lookup: Für jedes Token des Inputs wird in der Token-Embedding-Tabelle nachgeschaut, welche Werte die Dimensionen des Token haben. Es wird eine neue Matrix, also eine Tabelle erzeugt, in der jedem Token des Inputs aus dem Kontextfenster die aus der Token-Embedding-Matrix gelesenen Werte für die Dimensionen zugewiesen werden. In der Literatur gibt es ein Wirrwarr für die Bezeichnung dieser Matrix (Embedding Output, Input-Embedding oder Input Embedding Matrix), wir nennen sie einfach Kontext-Matrix. Sie existiert nur temporär im Computersystem, verschwindet wieder, wenn das Benutzeranliegen befriedigt ist und sollte nicht verwechselt werden mit der immer konstanten Token-Embedding-Matrix. Jedes Eingabe-Token hat damit einen Bedeutungs-Vektor, der erst einmal nur die aus dem Training des Systems erworbenen Werte für seine Dimensionen hat und noch so gut wie nichts über seinen Kontext in der Benutzeranfrage „weiß“.
Mit diesen „abstrakten“ Bedeutungen kennt sich die Statistik mit etablierten Verfahren wie Faktor- oder Clusteranalyse seit langem aus. Man wirft ein paar tausend Variablen in einen Topf, z.B. Eigenschaften von Viren, Polarlicht-Events oder Verhaltensweisen von Menschen, der Mathematik ist das völlig egal. Jede Variable wird mit allen anderen Variablen korreliert. Das Ergebnis ist die Korrelationsmatrix. Sie enthält die gegenseitigen Abhängigkeiten der Variablen voneinander, genauer deren Koinzidenz, also das Maß für die Stärke ihres gemeinsamen gleichzeitigen Vorkommens (was leider oft mit Kausalität verwechselt wird). Statistische Verfahren können aus dieser Korrelationsmatrix dann die größten gemeinsamen Dimensionen ermitteln, z.B. wenn Zuneigung, Liebe und Sympathie stark korrelieren, kann man daraus einen gemeinsamen Faktor - rein analytisch - herausdestillieren und ihm einen Namen geben, z.B. Affektivität. Dem statistischen Modell ist die Benennung egal. Für die optische Darstellung der Ergebnisse in einem Vektorraum kann das allerdings sehr nützlich sein (siehe Beispiel ).
In der nun erstellten Kontext-Tabelle haben wir eine Menge sehr abstrakter Informationen über die einzelnen Bedeutungsvektoren des Inputs. Damit die Information über die Position der Token in der Eingabe nicht verloren geht, wird der Bedeutungsvektor noch um eine Positionsinformation ergänzt, das sog. Position-Embedding. Dafür gibt es je nach Modell unterschiedliche Methoden.
Die Technik der Codierung von Positionen lässt sich nicht in ein paar Sätzen erklären. Wer es genauer wissen will, muss unter den Bezeichnungen für gängige Verfahren recherchieren: Klassisch ist die Sinus-/Kosinus-Positionskodierung, später abgelöst durch eigene im Training gelernte Embedding-Tabellen oder relative Positionserkennung, die sich nur für die Abstände eines Token von seinen Nachbarn interessiert. Heutiger Stand der Technik ist das Rotary Positional Embedding-Verfahren (RoPE). Das muss uns jetzt nicht weiter interessieren. Wichtig ist nur, dass nun auch zu jedem Token bekannt ist, an welcher Stelle es sich in der Eingabe befindet.
Das Wissen um die Position eines Token hilft dem Sprachmodell später dabei, die spezielle Bedeutung eines Token innerhalb seines Kontextes zu ermitteln, zum Beispiel bei Wörtern mit unterschiedlichen Bedeutungen wie das Wort Bank, das bekanntlich ein Geldinstitut oder ein Sitzmöbel bezeichnen kann, je nach Kontext.
Der Aufmerksamkeitsalgorithmus

Lesehilfe: Überall wo Sie den mathematischen Ausdruck
Matrix bzw.
Matritzen finden, können Sie sich anschaulich vorstellen, dass es sich um Tabellen handelt.
Nach diesen umfangreichen Vorarbeiten erfolgt nun der entscheidende dritte Schritt, die Anwendung des Aufmerksamkeits-Algorithmus. Die nachfolgend beschriebenen Schritte wiederholen sich in jeder der vielen inneren Schichten des Sprachmodells, von denen es bei den Top-Modellen über hundert gibt. Wir beginnen mit der ersten Schicht und schauen uns an, was dort passiert.
Attention Heads
Jede dieser Schichten hat sogenannte Attention Heads. Jeder dieser „Aufmerksamkeitsköpfe“ kümmert sich um jedes einzelne Token der Eingabe und schaut dabei immer auf alle Token des gesamten Inputs.
Der Aufmerksamkeitskopf verfügt über drei Werkzeuge, mathematisch dargestellt als Matrizen, die query (WQ), key (WK) und value (WV) genannt werden. Sie wurden im Training des Modells für jede Schicht „gelernt“.
Die drei Werkzeuge haben unterschiedliche Fähigkeiten. Mit ihnen werden die Kontextvektoren der Benutzereingabe bearbeitet, und sie stellen drei verschiedene Sichten auf jeden Kontextvektor her, die meistens mit Q, K und V bezeichnet werden.
Mathematisch sind das Matrixmultiplikationen für jeden Kontextvektor X mit den drei Werkzeug-Matrizen, heraus kommen die drei linearen Projektionen Q = XWQ, K = XWK und V = XWV.
Da die Kontextvektoren mit der beim Embedding erzeugten Positionsinformation versehen sind, ist dem Modell bekannt, an welcher Stelle im Text bzw. in welcher Nachbarschaft sich der gerade behandelte Token befindet.
In der Query-Projektion für den Kontextvektor befinden sich die Informationen, wonach das Token sucht. Zum Beispiel fragt ein Verb nach einem Subjekt oder Objekt, ein Pronomen nach einer Referenz worauf es sich beziehen kann und ein Adjektiv nach einem Namen oder Substantiv, das es beschreiben kann. Alles das sind abstrakte Informationen, die sich mit möglichen Beziehungen der Token untereinander beschäftigen und nichts über die inhaltliche Bedeutung sagen.
In der Key-Projektion für den Kontextvektor befinden sich die Informationen, was das Token für andere anzubieten hat, also wofür es gebraucht werden könnte. Es geht nur darum, wofür das Token relevant ist, wenn die Queries anderer Token nach ihm fragen. Das Token könnte zum Beispiel signalisieren, dass es eine Person bezeichnet, sich auf Pronomen beziehen kann, handeln kann oder passiv ist, lebendig oder tot ist usw.
In der Value-Projektion für den Kontextvektor befinden sich die Informationen, was das Token weitergeben wird, wenn für das Token Aufmerksamkeit entsteht. Das können semantische Beschreibungen, grammatische Rollen und allmögliche inhaltliche Details sein, alle möglichen Aspekte, die das Token in seinem Training „gelernt“ hat.
Query, Key und Value am Beispiel des Satzes Die Bank steht am Ufer zeigen
| Beispielsatz: Die Bank steht am Ufer |
| Vektor |
antwortet auf | Erläuterung |
| Query: |
Was suche ich? |
Der Query-Vektor beschreibt, wonach der betroffene Token Ausschau hält, z.B. das Token steht signalisiert: Ich bin ein Verb und suche nach einem Subjekt oder einem Objekt oder einer weiteren Erklärung. |
| Key: |
Was biete ich an? |
Der Key-Vektor beschreibt, welche Informationen der Token für andere bereit hält. Zum Beispiel bietet das Wort Bank in seinem Key-Vektor an ich bin ein Substantiv , ein Objekt , eine Apposition. |
| Value: |
Welchen Inhalt habe ich? |
Der Value-Vektor ist eine komprimierte Sammlung aller Informationen zu einem Token, die das Modell in seinem Training gelernt hat. Beispiel Bank mit mehreren verschiedenen Bedeutungen: Ich kann eine finanzielle Institution sein und habe mit Konten, Geld, Zinsen zu tun. Ich kann ein physikalisches Objekt sein, habe mit Holz, sitzen, Park, Geografie wie Ufer, Fluss .. zu tun.
verbergen |
Was wichtig ist: Die Bewertung
Nun folgt der für den Erfolg der Sprachmodelle so entscheidende Schritt: die Aufmersamkeitsbewertung.
Die Query-Key-Paare verschiedener Vektorsichten verhalten sich wie Schloss und Schlüssel. Zu den Query-Vektoren werden jetzt die passenden Keys gesucht. Dazu wird die Query eines Token mit den Keys aller Token verglichen, einschließlich mit sich selbst. Dann wird eine Rangliste gebildet, was am besten zusammenpasst. Das Ergebnis ist eine mit den Query-Key-Vergleichwerten gewichtete und mit Hilfe eines besonderen Verfahrens, der Softmax-Funktion auf eine 100-Prozent-Summe normierte Aufmerksamkeitsverteilung. Jedes Token ist nun im Bilde, wie stark es auf die anderen Token achten muss (einschließlich auf sich selbst).
Die Aggregation
Nun erfolgt die inhaltliche Aggregation. Jedes einzelne Token des Inputs kennt den Aufmerksamkeitswert für alle anderen Token des Inputs. Jetzt „weiß“ es, wofür es am stärksten aufmerksam ist. Mathematisch ausgedrückt kann man das genauer sagen: Es erhält die mit den Aufmerksamkeitswerten gewichteten Value-Werte der anderen Token. So entsteht ein neuer Vektor für jedes Token, das nun endlich auch den Namen Kontextvektor verdient, denn es ist mit Informationen aus seinem Kontext vollgestopft, genauer: Es enthält entsprechend seiner Relevanz gewichtete Informationen von den anderen Token. Die in der Regel 4096 Vektor-Dimensionen bieten genug Platz dafür. Die neue Bedeutung für das aktuelle Token ist nun so bearbeitet, dass sie die Bedeutung seines Kontextes, gewichtet mit der errechneten Aufmerksamkeit, berücksichtigt (mathematische Darstellung zeigen).
Mathematisch beschrieben spielt sich Folgendes ab: Die Matrizen der Query-Vektoren (Q) und Key-Vektoren (K) werden skalar multipliziert  . Jedes Element Sij dieser Score-Matrix bedeutet die Relevanz des Token j für den Token i. Die Werte werden nun skaliert. Das erfolgt durch Division jedes Matrixelements mit der Quadratwurzel aus der Dimensionszahl des Modells, Quadratwurzel deshalb, um die Größenunterschiede etwas zu harmonisieren. Dann erfolgt die Normierung mit Hilfe der Softmax-Funktion. Die Elemente Aij stellen die Aufmerksamkeitsgewichte dar, mit der das Token i auf das Token j achtet. Das Vektorprodukt Z = AV ist das Ergebnis, die neue Kontextmatrix mit den veränderten Bedeutungsvektoren für alle Token.
. Jedes Element Sij dieser Score-Matrix bedeutet die Relevanz des Token j für den Token i. Die Werte werden nun skaliert. Das erfolgt durch Division jedes Matrixelements mit der Quadratwurzel aus der Dimensionszahl des Modells, Quadratwurzel deshalb, um die Größenunterschiede etwas zu harmonisieren. Dann erfolgt die Normierung mit Hilfe der Softmax-Funktion. Die Elemente Aij stellen die Aufmerksamkeitsgewichte dar, mit der das Token i auf das Token j achtet. Das Vektorprodukt Z = AV ist das Ergebnis, die neue Kontextmatrix mit den veränderten Bedeutungsvektoren für alle Token.
Es gibt noch ein paar zusätzliche Regeln, zum Beispiel, dass die Token der letzten Abschnitte stärker zu beachten sind und dass bestimmte Direktiven bleibend hohe Aufmerksamkeit erhalten, egal an welcher Stelle sie im Input standen (z.B. antworte in deutscher Sprache), aber das ist nicht spielentscheidend.
Der neue Bedeutungsvektor bewegt sich also nicht mehr in exakt denselben Dimensionen mit denselben Werten wie der alte Bedeutungsvektor, sondern hat von den anderen Token des Inputs je nach Wichtigkeit etwas abbekommen. Wenn es sich beispielsweise um den Token Bank handelt, dürfte jetzt aus dem Kontext klar hervorgehen, ob eine Sparkasse, eine Parkbank oder eine Sandbank gemeint ist. In der nächsten Verarbeitungsschicht des Sprachmodells würde der neu zu bildende Value-Vektor dann deutlich anders aussehen als bisher und möglicherweise seine Mehrdeutigkeit bereits komplett verloren haben.
Wenn man sich das Spiel geometrisch vorstellt, so ist der neue Kontextvektor eine Verschiebung des alten Bedeutungsvektors und zeigt jetzt auf einen Punkt in diesem künstlichen hochdimensionalen Vektorraum, der etwas näher an den Orten anderer relevanter Vektoren und weiter weg von den Orten irrelevanter anderer Vektoren liegt. Dabei ist die mit Hilfe des Aufmerksamkeitsalgorithmus gemessene Aufmerksamkeit das Maß für Relevanz. Das System „versteht“ überhapt nicht die Bedeutung der bearbeiteten Wörter, hat buchstäblich davon keine Ahnung, sondern rechnet nur mit den Beziehungen der Bedeutungsvektoren untereinander.
Die Abläufe wurden wegen der besseren Erklärbarkeit bisher sequenziell geschildert, laufen aber im Inneren des Sprachmodells alle gleichzeitig ab. Das ist der Vorteil der Vektorrechnung bei der Matrixmultiplikation: Alles passiert zeitgleich, auf einen Schlag. Es ist als ob mit einem Blick weit zurück geschaut werden kann (bis an den Anfang des Inputs), sozusagen in die Vergangenheit, und - wie wir noch sehen werden - auch gleichzeitig weit nach vorne.
Die Bedeutungsvektoren der einzelnen Token wurden ja bereits im Embedding mit den „Erfahrungen“ des Sprachmodells aus seinem Training aufgetankt, buchstäblich mit aller Klugheit und Blödheit infiziert, die sich in den Trainingsdaten befindet. Die Arbeit des Aufmerksamkeitsmechanismus ergänzt dieses „Wissen“ mit Informationen aus dem Kontext des Benutzer-Inputs.
Die mathematische Formel für die doch recht komplexen Vorgänge schaut ziemlich einfach und elegant aus, wen es interessiert, bitte Erklärung zeigen klicken.
Jede Menge Tricks
Die Modelle arbeiten zusätzlich mit einer Menge mathematischer und praktischer Tricks. Einer davon ist, dass pro innerer Schicht des Modells nicht mit einem Aufmerksamkeitskopf gearbeitet wird, sondern mit mehreren (sog. Multi-Head-Attention). Meist gibt es acht oder zwölf dieser Köpfe.
Die Modelle sind so trainiert, dass ihre Aufmerksamkeit sich bei jedem Kopf auf unterschiedliche Dinge richtet, zum Beispiel für die Aufmerksamkeitsköpfe in der ersten Schicht:
- Nächster-Nachbar-Kopf: achtet nur darauf, welches Wort links oder rechts vom Token steht.
- Grammatik-Detektor: sucht nach Präpositionen oder Artikeln für den Token.
- Trennzeichen-Kopf: sucht nach Kommata oder anderen Trennzeichen.
- Referenz-Kopf: sucht bei Pronomina wie er, sie, es nach dem wahrscheinlichsten voranstehenden Substantiv, auf das sich das Pronomen beziehen könnte.
- .....
Alles beginnt recht bescheiden mit einer Art Oberflächen-Analyse über die Position der Token und ihre Nachbarschaft. Spätere Schichten des Modells können dann auf diesen Ergebnissen aufbauen. Umgangssprachlich ausgedrückt wird schrittweise versucht, Form und Inhalt zusammenzubringen, um sich an die eigentliche Bedeutung heranzupirschen. Typiche Aufgaben der Aufmerksamkeitsköpfe in späteren Schichten sind dann:
- Disambiguierungs-Kopf: versucht, mehrwertige Bedeutungen aufzulösen, sucht z.B. bei Bank nach dem Kontext in der Nachbarschaft des Token.
- Themen-Cluster-Kopf: sucht nach allen Token, die zum selben Thema (gemäß Information aus dem Systemtraining) gehören und reichert den Token-Vektor bei Erfolg um die Bezeichnung des Themas an.
- Logik-Detektor: achtet auf Konjunktionen wie weil, daher, um, obwohl und versucht, Verbindungen zu finden, die vom Benutzer später als kausale Kette interpretiert werden können.
- Wissens-Kopf: versucht, Eigennamen (z.B. von Politikern) mit dem aus dem „Weltwissen“ des Modells gelernten Attributen zu verbinden.
- Sentiment-Kopf: achtet auf Adjektive oder Adverbien, die eine Bewertung ausdrücken, um eine emotionale Färbung oder Stimmung festzuhalten.
- .....
Technisch passiert hier immer das Gleiche: Der Query-Vektor des in die Mangel genommenen Tokens wird mit den Key-Vektoren der anderen Token abgeglichen, ruft für die höchsten Wahrscheinlichkeiten des Matchings die Value-Vektoren der gefundenen Token ab und addiert sie gewichtet mit ihren Wahrscheinlichkeitswerten zu dem schon aus der Bearbeitung in früheren Schichten angereicherten Kontext-Vektor des gerade bearbeiteten Token. So werden die Bedeutungsvektoren der Token immer mehr mit Informationen aus ihrem Kontext aufgeladen.
Sparsamer Umgang mit Rechenpower
Die Arbeit mit mehreren Aufmerksamkeitsköpfen spart Rechenpower. In den neueren Modellen mit einer hohen Dimension zum Beispiel dmodel = 4096 für den Vektorraum des Gesamtmodells haben die einzelnen Matrizen (Q,K und V) nur einen Bruchteil der Dimension des Modells, berechnet nach der Formel dk = dmodel dividiert durch die Anzahl der Köpfe. Bei acht Köpfen sind das dann nur noch 512 Dimensionen, immer noch viel Platz, um Informationen unterzubringen. Man will herausgefunden haben, dass auf diese Weise keine oder kaum wesentliche Information verloren geht.
Praktische Erfahrungen
Dass man die Wahrscheinlichkeitswerte vor ihrer Normierung nicht einfach durch die Dimensionszahl dk teilt, sondern durch die Wurzel  ist eine rein statistische Entscheidung der Entwickler (Vaswani et al. in dem berühmten Google-Paper Attention is all you need aus dem Jahr 2017). Denn bei sehr hohen Werten wird die Softmax-Funktion, mit der alles normiert wird, extrem „steil“, d.h. ein einzelner hoher Wert bekommt fast 100 Prozent der Aufmerksamkeit, während alle anderen fast nichts mehr abbekommen, also ihre Werte gegen Null gehen. Dies würde zu stark verzerrten Informationen führen und wäre schon für das Lernen des Modells bei seinem Training hinderlich gewesen und jetzt erst recht bei der Suche nach einer Antwort auf die Benutzereingabe.
ist eine rein statistische Entscheidung der Entwickler (Vaswani et al. in dem berühmten Google-Paper Attention is all you need aus dem Jahr 2017). Denn bei sehr hohen Werten wird die Softmax-Funktion, mit der alles normiert wird, extrem „steil“, d.h. ein einzelner hoher Wert bekommt fast 100 Prozent der Aufmerksamkeit, während alle anderen fast nichts mehr abbekommen, also ihre Werte gegen Null gehen. Dies würde zu stark verzerrten Informationen führen und wäre schon für das Lernen des Modells bei seinem Training hinderlich gewesen und jetzt erst recht bei der Suche nach einer Antwort auf die Benutzereingabe.
Damit die ursprünglichen Bedeutungen der einzelnen Token nicht durch die beschriebenen beachtlichen Manipulationen verloren gehen, wird ein weiterer Trick angewendet, die Residual Connections. Der neu erzeugte Kontextvektor wird einfach an die bisherige Kette der Token-Vektoren hinten dran gehängt, nach der Formel
Neues Output = alte Eingabe + Ergebnis von Attention(Q,K,V).
Dadurch wird verhindert, dass das Modell ursprüngliche Bedeutungen „vergisst“. Selbst wenn die Anwendung der Attention-Formeln zu gar keinem Ergebnis führen würde, bleibt die ursprüngliche Information erhalten (dafür gibt es auch noch einen Fachjargon, und der heißt Skip-Connections).
Nachbereitung
Wenn die Aufmerksamkeits-Köpfe ihre Arbeit getan haben, erfolgt die Nachbearbeitung. Bisher liegen die Informationen nur in "Splittern" vor. Jeder Kopf hat eine eigene kleine Teil-Antwort geliefert. Nun muss daraus wieder für jedes Token ein konsistenter, hochdimensionaler Vektor werden. Dazu werden die in ihrer Dimension reduzierten Ergebnis-Vektoren der einzelnen Aufmerksamkeitsköpfe aneinandergereiht, so dass daraus ein Vektor mit der Dimension des Modells entsteht. Dieser Vektor als Gesamtergebnis der Aufmerksamkeit wird jetzt zu dem alten Kontext-Vektor nach den Regeln der Vektoraddition addiert. Falls die Aufmerksamkeits-Behandlung nichts gebracht hat, bleibt auf jeden Fall das alte Ergebnis erhalten. Das Modell hat also nichts „vergessen“.
Das zusammengemischte Ergebnis wird jetzt in ein Feed-Forward-Netzwerk (FFN) geschickt.
Ein Feed-Forward-Netz ist ein einfaches Neuronales Netz, bei dem der Informationsfluss durch die Schichten des Netzes nur vorwärts erfolgt. Es gibt keine Rückwärtsschleifen wie bei anderen Neuronalen Netzen. Einem Feed-Forward-Netz kann man durch Training beibringen, Muster zu erkennen und Begriffe zu kategorisieren.
Das Feed-Forward-Netz ist sehr flach. Es hat nur zwei Schichten (einen Expansion und einen Contraction Layer). Für die erste Schicht wird jeder Token-Vektor auf seine in der Regel vierfache Dimensionszahl „aufgeblasen“. Das geschieht, um Platz für unterschiedliche Operationen zu haben. Während der Aufmerksamkeits-Algorithmus auf die Beziehungen der Token untereinander geachtet hat, behandelt das FFN jedes Token für sich und reichert es mit Informationen an, die es passend zu den vorhandenen Informationen im „Allerwelts“-Wissen des Sprachmodells findet. Die Aktivierungsfunktionen der Schicht sorgen durch Null-Setzen von negativen Aufmerksamkeitswerten (ReLU-Verfahren) oder ähnlichen sanfteren Methoden (z.B. GELU-Verfahren) dafür, dass Wichtiges verstärkt und Unwichtiges weggelassen oder abgeschwächt wird. Die letzte Schicht dampft die „aufgeblasenen“ Vektoren durch geeignete Komprimierungsverfahren wieder auf ihre alte Größe zurück (mehr über die Arbeit des FFN zeigen).
Das FFN hat im Training des Modells eine implizite Entscheidungslogik gelernt, zum Beispiel
- Regel 1: Merkmalsverstärkung und Unterdrückung: Nehmen wir den Token Bank aus dem Beispielsatz Die Bank steht am Ufer. Der Vektor für Bank hat viele Dimensionen, einmal die aus dem Vokabular des Sprachmodells gelernten Dinge wie: eine Bank kann ein Finanzinstitut, ein Sitzmöbel, eine geologische Besonderheit und noch viele andere Dinge sein. Die in der Aufmerksamkeitsphase entstandene Kontext-Information hat bereits geklärt, dass die Wahrscheinlichkeit für ein Finanzinstitut kleiner ist als die Wahrscheinlichkeit für ein Möbel. Aber endgültig entschieden ist die Angelegenheit noch nicht. Die Anwendung der Verstärkung-Unterdrückung-Regel veranlasst das FFN, den Dimensionswert für Möbel zu erhöhen und den für Finanzinstitut runterzusetzen. Würde der Möbel-Wert auf 1 gesetzt, dann wäre die Sache hier bereits entschieden. Doch dafür ist es noch zu früh.
- Regel 2: Merkmalsverstärkung durch typische Kombinationen: Zum Beispiel wenn die Vektor-Dimension für Möbel-Assoziation einen Wert besitzt und ebenso die Dimension für Draußen-Ort, dann sorgt diese Regel dafür, dass die möglichen Dimensionen witterungsbeständig und öffentlicherOrt aktiviert werden. Die Folge ist, dass der Null-Wert für die beiden letztgenannten um eine ganz geringe Zahl erhöht wird. Damit könnten nachfolgende Schichten rechnen, d.h. „sensibilisiert“ werden für Attribute, ob die Bank vielleicht rostig ist oder der Stadt gehört.
- Regel 3: Syntaktisch-semantische Konsistenz: z.B. wenn steht als Verb im Satz vorkomt, dann wird für Bank die Dimensionen PhysikalischesObjekt und statisch aktiviert und Institution und Finanzen deaktiviert.
- .........
Die Namensbezeichnungen für die Regeln sind hier in den Beispielen willkürlich benannt. Das Modell arbeitet nur mit Faktoren, die Gemeinsamkeiten beschreiben können und interssiert sich in keiner Weise dafür, ob und wie sie namentlich benannt sind.
Was daraus folgt, wieder an einem Beispiel: Angenommen, ein FFN-Neuron hat in seinem Training gelernt, Natur-Sitzbänke zu erkennen (im Klartext: zu reagieren, wenn ein Impuls die Dimensionen Natur und Sitzbank enthält). Dem behandelten Token-Vektor würde ein Wert zugeschrieben, dass es sich hier um eine Sitzbank im Freien handelt. Nach Durchlauf durch das FFN könnte der Bank-Vektor dann folgende Dimensionswerte haben:

Dimensionswerte des Bedeutungsvektors Bank nach Durchlauf durch das Feed-Forward-Netz.
Quelle:Durchgeführte Berechnung nach Vorgaben durch DeepSeek
Die Namen für die Vektordimensionen sind wiederum nur ausgedacht. Niemand hat den Dimensionen des Sprachmodell-Vektorraums Namen gegeben. Die Dimensionen sind künstliche Artefakte, deren Ausprägung allein durch Statistik gewonnen wurde, nämlich aus den Korrelationen der Millionen Token des Sprachmodell-Vokabulars untereinander. Wenn man meint, sie interpretieren zu können, kann man ihnen Namen geben.
Alles hängt von den Trainingsdaten des Sprachmodells ab. Sie mögen sich selber Gedanken machen, wie alles sich wieder ändern würde, wenn das zukünftige Training des Modells mit völlig anderen Daten erfolgen würde, die mit Posts aus Zuckerbergs Facebook oder Grok von Elon Musk angereichert wären.
verbergen
Mixture of Experts
Es ist das Verdienst von DeepSeek, die US-amerikanische Konkurrenz aufgeschreckt zu haben und sie veranlasst zu haben, schleunigst nachzuziehen: Gemeint ist das Konzept Mixture of Experts (MoE). Die Idee besteht darin, das eine FFN jeder Schicht des Sprachmodells durch bis zu acht kleinere Feed-Forward-Netze zu ersetzen, die auf verschiedene Fachgebiete spezialisiert sind, sogenannte Experten. Ein kleines Gating-Netzwerk übernimmt dabei eine Router-Funktion und entscheidet pro Token, welche zwei dieser FFN-Experten gerade rechnen dürfen, die anderen FFN haben derweil Pause. Dies spart Ressourcen ohne nennenswerten Qualitätsverlust.
Am Ende der Schicht
Die Nachbereitung durch das Feed Forward-Netz hat dafür gesorgt,
- dass Mehrdeutigkeiten aufgehoben oder zumindest abgebaut wurden,
- dass die Input-Token mit aus dem Training des Systems gelernten Attributen angereichert wurden und
- dass das Modell für ebenfalls aus dem Training gelernte Vorhersagen, wie es weitergehen könnte, vorbereitet wurde.
So ist ausgeschlossen, dass das System die Sitzbank am Ufer aus dem obigen Beispiel Kredite anbieten lässt. Sollte das trotzdem vorkommen, nennt man das Halluzination.
In der Praxis laufen die Aufmerksamkeitsvorgänge ohnehin nicht wie hier geschildert für jedes Token einzeln ab, sondern sie werden sozusagen gestapelt und dann gebündelt verarbeitet. Dies geschieht hauptsächlich aus Performance-Gründen, denn die Spezialchips der KI-Computer sind besonders leistungsstark in der blitzschnellen Verarbeitung großer Matrizen. Statt unzähliger einzelner Rechenoperationen hat der Computer auf diese Weise immer nur mit einem Vorgang zu tun.
Die nächsten Schichten
Wenn das alles erledigt ist, geht die Reise weiter zur nächsten Schicht des Sprachmodells. Davon gibt es für die Hochleistungssysteme von Google und OpenAI bis zu 120 (DeepSeek ist etwas sparsamer und kommt mit der Hälfte aus, Stand Januar 2026).
Das Spiel beginnt für jede Schicht von Neuem, aber mit den in der vorangegangenen Schicht veränderten Query-, Key- und Value-Werten für jedes einzelne Token des Inputs. Die einzelnen Schichten haben spezialisierte Aufgaben.
Die direkt nach der Eingabe liegenden Schichten kümmern sich vor allem um linguistische Aspekte: Sie erkennen Wortenden und Wortstände, erkennen, ob ein Token als Substantiv oder Verb funktioniert, und ihre Aufmerksamkeits-Köpfe schauen meist nur auf die unmittelbaren Nachbarwörter, um z.B. festzustellen, welcher Artikel zu welchem Substantiv gehört. Sie bereinigen Mehrdeutigkeiten und reichern die Vektoren der Token, wie oben geschildert, mit zusätzlichen Informationen an.
Die mittleren Schichten der Modelle kümmern sich verstärkt um logische und semantische Beziehungen der Token. Sie versuchen, Pronomen mit den zugehörigen Namen zu verbinden, auch wenn diese weit entfernt im Text liegen. Sie erkennen Nebensatzstrukturen und logische Abhängigkeiten und Subjekt-Obkekt-Beziehungen und registrieren den Hauptinhalt größerer Zusammenhänge wie Textabschnitte.
Je näher die Schichten der Ausgabeschicht kommen, desto mehr geht es um strategische Fragen, die Vorbereitung des Antwort-Ergebnisses. Hier wird stärker auf das im Training des Systems gelernte sogenannte Weltwissen zugegriffen. Außerdem erfolgt bereits die Aufgaben-Spezialisierung. Wenn es sich um eine Benutzer-Frage handelt, bereiten diese Schichten die Information so vor, dass sie wie eine Antwort klingt. Wenn man sich eine Liste wünscht, achtet das Modell auf Einhaltung dieser Präsentationsform. Wenn eine Geschichte verlangt wurde, wird auf erzählenden Stil umgeschaltet.
Auch die Aufmerksamkeitsköpfe der verschiedenen Schichten haben unterschiedliche Spezialisierungen, wie bereits am Beispiel der ersten internen Schicht geschildert.
Die Ausgabeschicht
Nach Durchlauf durch die letzte interne Schicht liegt eine mit vielen komplexen Informationen aufgeladene Vektormatrix vor. Sie enthält die Kontext-Vektoren aller Token des kompletten Kontextfensters der Benutzereingabe. In den Dimensionen eines jeden Kontext-Vektors ist alles verpackt, was das Modell beim Durchlauf durch die vielen internen Schichten für den Token errechnet und eingesammelt hat.
Die Grundausstattung
Die nun folgende allerletzte Schicht des Sprachmodells ist die Ausgabeschicht. Sie kümmert sich nicht mehr um Aufmerksamkeiten, sondern hat die Aufgabe, das mathematische Vektor-Konstrukt zurück in Sprache zu verwandeln. Sie verfügt über eine Output-Matrix, auch De-Embedding oder LM-Head genannt. Sie ist das Gegenstück zur Token-Embedding-Matrix ganz am Anfang des Sprachmodells. Während die Token-Embedding-Matrix für jedes Token des Vokabulars nur die Werte für die Koordinaten im hochdimensionalen semantischen Raum enthält, stellen die Werte der Token der Output-Matrix dar, wie ein interner Zustand in den Dimensionen des Modells aussehen muss, damit der Token (also die ihm zugeordnete Zeichenfolge) gemeint ist. Das ist nicht deterministisch in dem Sinne, dass ein Token genau das ist, was in seinen Dimensionswerten steht. Sie geben eher eine Auskunft darüber, für welche Werte im Semantischen Vektorraum sie stark wählbar sind. Die Werte beider Matrizen (Input-Embedding- und Output-Matrix) müssen nicht unbedingt verschieden sein, ihre Funktion ist eine andere. Die Embedding-Matrix ist für das Lesen eines Token-Vektors, die Output-Matrix eine Prüfung, wie gut innere Zustandswerte eines Vektors zu einer Token-Repräsentation passen. Die Embedding-Dimensionswerte beschreiben, wie ein Token im Modell verortet ist, die Output-Dimensionswerte beschreiben, auf welche internen Zustände dieses Token anspringt.
Diese Werte haben nichts mit der Bedeutung der Token zu tun, sondern beschreiben nur ihre Verbindungsmöglichkeiten untereinander, im Sinne was passt bei welchen Konstellationen von Kontextmerkmalen zu dem Token wie gut, sodass er bevorzugt ausgewählt werden könnte. Die Dimensionen beschreiben auch nur aus der Statistik des Trainings gelernte Beziehungen wie
- steht häufig am Satzanfang,
- ist typisches Wort am Beginn einer Antwort,
- passt grammatisch zu Verben,
- kommt oft in technischen Zusammenhängen vor,
- passt zu erklärenden Texten,
- ist typisch nach Zahlen,
- ist passend nach einer Frage,
- passt zu einem bestimmten Stil,
- und ein paar tausend weitere ähnliche Merkmale.
Den Dimensionen Namen zu geben, ist reine Willkür, sie beschreiben lediglich Wahrscheinlichkeitswerte für passende Beziehungen, die durch Statistik gefunden wurden. Die Output-Tabelle liefert also nur Informationen über Bedingungen, wie gut der betroffene Token als passende sprachliche Fortsetzung geeignet ist.
Die Suche nach dem ersten Wort
Jetzt trifft die Konzextvektor-Matrix auf die Output-Matrix. Das wird eine Matrixmultiplikation - ein Freudenfest für die Mathematik, denn das können die Rechner blendend gut. Doch schauen wir uns an, was hier passiert:
Nun haben wir das eigentliche Sprachmodell verlasssen und sind in der Ausgabeschicht gelandet, und die liegt in der Herrschaftszone des Decoders.
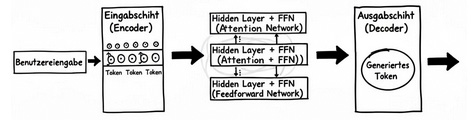
Der lange Weg eines Token durch das Sprachmodell
Stat drei können es auch hundert hidden layer seinDas Modell greift sich den Kontext-Vektor des letzten Token der Benutzereingabe und konfrontiert ihn mit der Output-Matrix. Das bedeutet, der Kontextvektor des letzten Token wird mit jedem einzelnen Token des Vokabulars abgeglichen, so als ob er fragen könnte: Wer passt am besten zu mir. Das Ergebnis dieser Begegnung (einer skalaren Vektormultiplikation) ist eine lange Liste von Zahlen, die sogenannten Logits.
Der nächste Schritt ist die Umwandlung dieser buckligen Zahlen in eine Wahrscheinlichkeitsverteilung. Dazu dient wieder einmal die schon vom Aufmerksamkeitsalgorithmus bekannte Softmax-Funktion.

Die Softmax-Funktion
Zur Erinnerung: Die Softmax-Funktion berechnet aus einer Liste von Zahlen eine Wahrscheinlichkeitsverteilung in Form von gewichteten Prozentanteilen, bei denen jede Zahl im Vergleich zu allen anderen bewertet wird und die größte Zahl sowie die absoluten Werte der Zahlenabstände überproportional stark gewichtet sind. Die Summe der berechneten Zahlen ist immer 1, entsprechend 100 Prozent.
Sie ermittelt über das ganze Vokabular hinweg die Wahrscheinlichkeiten dafür, wie gut das jeweilige Wort für die nächste Fortsetzung des (bisher erzeugten) Antworttextes passt. „Passen“ meint hier sprachlich anschlussfähig, statistisch plausibel und konsistent mit dem bisherigen Text (im Sinne von typisch für ähnliche Texte aus dem Training des Systems). Beim ersten Wort ist der bisherige Text nur das Benutzer-Prompt (oder ein spezielles Start-Token). Noch ist nichts entschieden.
Die Auswahlentscheidung
Der Decoder wendet ein Auswahlverfahren an. Dazu gibt es mehrere Möglichkeiten:
- Greedy Decoding: Der Token mit der höchsten Wahrscheinlichkeit wird gewählt.
- Sampling: Es erfolgt eine zufallsgesteuerte Auswahl gewichtet nach Wahrscheinlichkeiten, meist in Verbindung mit
- Top-k oder Top-p, wobei bei Top-k die Auswahl auf eine festgelegte Zahl von Wahrscheinlichkeiten (z.B. die drei höchsten Werte) erfolgt oder bei Top-p so viele Wahrscheinlichkeiten berücksichtigt werden, bis ihre Summe eine bestimmte Prozentzahl (z.B. 90 Prozent) erreicht hat.
Ausgewählt wird nur ein Token, das kann ein Wort, Wortteil, ein Satzzeichen oder bloß ein Leerzeichen sein. Der Token kann nun auf dem Bildschirm erscheinen. Das System hat noch keine Ahnung, wie es weitergeht, sein Blick in die Zukunft hat genau ein Token weit gereicht.
Bevor das Modell eine Entscheidung trifft, kann es, abhängig vom Modell, noch weitere Parameter berücksichtigen, zum Beispiel die Stimmung oder Wort-Temperatur.
Was da alles geht, hat ChatGPT mit seinen Versionen ab 5.1 auf die Spitze getrieben, mit Auswahlmöglichkeiten für den Stil und Tonfall der Antworten wie standard, professional, freundlich, aufrichtig, skurril, effizient, nerdig oder zynisch, und damit nicht genug, noch drei Stufen für herzlich, enthusiastisch, ob mehr Energie und Begeisterung gefragt ist oder ob man es ruhiger angehen will.
Technisch wird das umgesetzt durch das Sampling, eine Behandlung mit Zahlenwerte auf einer Temperatur-Skala, wobei niedrige Werte (0.1 bis 0.5) eher einen logisch-sachlichen Ton bedeuten, Werte zwischen 0.5 und 1 für SweetSpot stehen, eine Mischung aus präzise und natürlich und hohe Werte für angebliche Kreativität (1.0 - 1.5) oder was immer die Entwickler sich ausgedacht haben. Die mit hohem Aufwand errechnete Logit-Zahl wird einfach durch den beschriebenen Faktor geteilt.
Wenn das alles geschehen ist, wird die Softmax-Funktion angewendet und macht wie beschrieben aus den Logit-Zahlen Prozentwerte für eine Wahrscheinlichkeitsverteilung, die jetzt anders ausfällt als ohne dieses Sampling.
Was das bedeutet, sollten wir uns an einem Beispiel klarmachen: Nehmen wir an, in einer Frage nach einem Kochrezept-Vorschlag hat das System für eine Zutat die Logit-Zahlen 15.4 für Risotto, 12.1 für Reis und 4.2 für Rigatoni gefunden. Nehmen wir weiter an, das Modell hat uns eine niedrige Sprach-Temperatur von 0.2 beschert, für sehr sachliche Darstellung. Dann errechnet das System nach Division der genannten Zahlen durch 0.2 für Risotto einen Wert von 77.0, für Reis 60.5 und für Rigatoni 21.0 aus. Die absoluten Abstände der Zahlen sind hoch.
Im zweiten Fall nehmen wir an, wir hätten eine enthusiastische, kreative Sprach-Temperatur gewählt oder was immer das Marketing des Chatbot-Anbieter sich ausgedacht hat, mit einem Wert von 1.5. Dann erhalten wir nach Division der Logit-Zahlen durch 1.5 für Risotto 10.3, für Reis 8.1 und für Rigatoni 1.3. Jetzt fällt der Abstand der Zahlen relativ klein aus.
Wenn das Sprachmodell jetzt die Softmax-Funktion für die errechneten Zahlen anwendet, könnte es - grob geschätzt - im ersten Fall eine Wahrscheinlichkeitsverteilung von 90 Prozent für Risotto und weniger als 1 Prozent für Rigatoni berechnen, im zweiten Fall mit den geringeren Abständen der Logit-Zahlen eine Wahrscheinlichkeitsverteilung für Risotto von nur noch 40 Prozent und für Rigatoni von 10 Prozent. Rigatoni haben nun die Chance von 1 zu 10, für das Gericht ausgewählt zu werden, im ersten Fall waren die Chancen schlechter als 1 zu 100.
Die Softmax-Funktion hat uns nun die Wahrscheinlichkeitsverteilung für jedes Token geliefert. Bei einer Wort-Temperatur von 0 wird immer das Wort mit der höchsten Wahrscheinlichkeit gewählt (im obigen Beispiel Risotto), in anderen Fällen erfolgt ein stochastisches Sampling: Nach dem Prinzip einer gewichteten Zufallssteuerung tifft das System, durch einen Zufallsgenerator gesteuert, eine Auswahl entsprechend der berechneten Wahrscheinlichkeiten.
Diese Architekturentscheidung wurde aus Erfahrung getroffen. Wenn immer der Wert mit der höchsten Wahrscheinlichkeit gewählt wird, neigt das System dazu, in logische Schleifen zu geraten und Sätze ständig zu wiederholen (sog. Greedy Decoding). Das Sampling dagegen bewirkt, dass die Sprache einen „menschlicheren“ Charakter erhält, so sagen die Entwickler, nicht so roboterhaft wirkt und ein kleines Momentum von Unvorhergesehenheit vortäuschen kann.
Die nächsten Wörter
Um weiter fortzufahren, wendet das Modell jetzt einen wichtigen Trick an: Es setzt den gefundenen Token (genauer: seinen Vektorwert) an das Ende des Benutzereingabe und startet die ganze Prozedur von neuem. So muss das Modell erneut suchen und die ganze bisherige Sequenz wieder von vorne starten. Es muss wieder durch alle Schichten des Modells hindurch, um herauszufinden, mit welchem Token die Präsentation des Ergebnisses fortgesetzt werden soll.
Technisch läuft das etwas anders ab, denn es wäre viel zu teuer und vor allem viel zu langsam, für jedes neue Wort den ganzen Text von Anfang an neu zu berechnen. Deshalb nutzt das Modell einen speziellen Speicher für die bereits errechneten Ergebnisse, den Key-Value-Cache. Die Berechnungen für die alten Token (ihre Keys und Values aus der Attention-Schicht) werden in diesem Arbeitsspeicher auf besonders geeigneten Grafikkarten zwischengespeichert. Für das nächste Wort muss das Modell also nur noch einen neuen Query-Vektor berechnen und ihn mit den bereits gespeicherten Keys der alten Wörter vergleichen. Für alle vorangegangenen Schritte werden die gespeicherten Ergebnisse verwendet.
Außerdem achtet das Modell auf besondere Token, die ein Satz- und Absatzende bedeuten und sorgt durch eine interne Regel für die Attention Heads dafür, dass die Hauptaufmerksamkeit bei den letzten Absätzen liegt und der vorangegangene Text nur noch eine geringere Aufmerksamkeit erhält. Erfahrungsgesteuert werden bestimmte Benutzeranweisungen abweichend behandelt, z.B. Vergiss den bisherigen Kontext oder Antworte nur auf Deutsch.
Die meisten Modelle haben eine Größenbeschränkung ihres Kontextfensters (Benutzer-Prompt plus bisherige Frage-Antwort-Historie plus Systemanweisungen plus eventuelle weitere Informationen aus Internetsuche oder anderen Quellen). Stößt ein Sprachmodell an diese Grenze, kann es die Anfänge der Benutzereingabe kürzen, in der Annahme, dass sie keinen großen Einfluss mehr auf die Ausgabe haben.
Magische Momente
Manchmal kann man auf dem Bildschirm beobachten, wie Wörter verschwinden oder ganze Textteile abgebrochen und neu geschrieben werden. Auch wenn das aussieht wie von Zauberhand geschrieben, beruht das nicht auf Irrtümern des Sprachmodells. Das Modell produziert wie gehabt einfach Token auf Token für die Ausgabe.
Wenn Texte kurz erscheinen und dann wieder verschwinden, liegt es daran, dass die Token zwar berechnet, aber noch nicht bestätigt wurden. Wenn ganze Texte verschwinden oder abgebrochen werden, hat meistens ein interner Kontrollmechanismus des Decoders eingegriffen. Einige davon haben wir schon kennengelernt, den Temperatur-Mechanismus, das Top-k- oder Top-p-Verfahren, das nur die höchsten der wahrscheinlichen Möglichkeiten zulässt. Zusätzlich verfügt der Decoder über Belohnungs- und Bestrafungsmechanismen, die dafür sorgen, dass Wörter sich nicht mehrfach wiederholen und Alternativen berücksichtigt werden, wenn die Wörter bzw. Token für den eigentlichen Kandidaten sich zu oft wiederholt haben.
Externe Kontrollmechanismen, die außerhalb des eigentlichen Sprachmodells verankert sind, können veranlassen, bestimmte Wörter zu unterdrücken oder zu bevorzugen; „problematische“ Ausgaben werden blockiert, umformuliert, ersetzt oder abgebrochen. Ein paar harte Regeln entscheiden z.B. dass bestimmte Wörter in bestimmten Kontexten schlicht verboten sind. Natürlich gibt es auch Längen-, Zeit- und Kostenkontrollen (maximale Tokenzahl, Zeitlimit, Budgetgrenze bei Bezahlversionen) sowie demnächst vermehrt Mechanismen für die Einblendung von Werbung. Weiterhin besteht der Verdacht, dass bei bestimmten Fragen nach speziellen Angelegenheiten main-stream-konforme Antworten eingeblendet werden, auch wenn man danach nicht gefragt hat, zum Beispiel bei Nachfragen zu belastbaren Studien über Corona-Impfschäden oder bei Fragen zu Details chinesischer Landkarten (siehe Beispiel).
Das Ende der Antwort
Bleibt noch zu klären, wie ein Chatbot feststellt, dass er aufhören soll. Das Vokabular des Sprachmodells kennt auch Token für das Ende der Antwort (<eos> für end of sequence) und bricht ab, wenn die Wahrscheinlichkeiten für eine Fortsetzung geringer erscheinen als die Wahl des Abschluss-Token. Das Ende wird also nach demselben Wahrscheinlichkeitsspiel gefunden wie jedes andere Token. Natürlich hört jedes Sprachmodell auch auf, wenn eine andere externe Regel des Decoders dafür sorgt.
Anwendungen
Sich auf die Chatbots zu konzentrieren, hat den Vorteil, dass inzwischen alle wissen, was das ist. Dagegen sind andere Anwendungsfelder der Künstlichen Intelligenz etwas aus dem Fokus der öffentlichen Wahrnehmung geraten wie Maschinelles Lernen, Prognosemodelle, KI in der Medizin und den Biowissenschaften, Robotik, Anwendungen in der industriellen Produktion, Einsatz in Spielen und sogar in der Emotionserkennung und -simulation. Anwendungen im militärischen Bereich werden immer deutlicher in ihrem bedrohlichen Charakter.
Systeme mit der Fähigkeit zur Mustererkennung, gleich welcher Art einschließlich der Sprachmodelle hinter den Chatbots, werden in zunehmendem Maß als Programmschnittstellen, sog. Application Programming Interfaces (APIs) angeboten und können damit in beliebige andere Anwendungsprogramme integriert werden. Dies macht einmal mehr deutlich, dass es sich bei der Künstlichen Intelligenz um eine Universaltechnik handelt, die nicht mehr wegzudenken ist.
Wir konzentrieren uns im Folgenden auf zwei beispielhaft herausgegriffene Bereiche.
Bildverarbeitung
Im bisherigen Text haben wir uns darauf konzentriert, die Leistungen der Künstlichen Intelligenz am Beispiel des Umgangs mit Sprache deutlich zu machen. Was wir dabei beschrieben haben, war eine Mixtur von Mustererkennung, Statistik und Wahrscheinlichkeitsrechnung. Wir haben gesehen, wie gut das mit Sprache funktioniert. Doch es funktioniert genauso gut mit Bildern. Nur sind die Token jetzt keine Wortbestandteile, sondern kleine künstlich erzeugte Bild-Fragmente. Ein Bild wird in kleinste flach gemachte Pixel-Quadrate (16x16 Pixel) zerlegt und jedes davon zu einem Patch-Embedding-Vektor transformiert, mit einem Aufmerksamkeits-Mechanismus bearbeitet, und alles geht so ähnlich weiter, wie für den Umgang mit Text geschildert.
Die Erfolge KI-gesteuerter Bildverarbeitung sind erstaunlich bis verstörend, sodass ihr Missbrauch als Fakes inzwischen sogar Politiker wachgerüttelt hat. Programme wie Midjourney, Dall-E, Sora von OpenAI, NanoBanana von Google oder das momentane Shooting-Star-Produkt Flux des Freiburger Start-up Black Forest Labs, nicht zu vergessen auch Photoshop und Lightroom von Adobe sowie zahlreiche kleinere Helfer-Programme sind als Handwerkszeug von Grafikern nicht mehr wegzudenken und machen sich in vielen Anwendungsbereichen breit, ähnlich wie die Chatbots.
Und ganz ähnlich wie mit der Bildbearbeitung verhält es sich mit Video- und Tonbearbeitung. Sprache, Bild und Ton, einmal digitalisiert, sind das gleiche Futter für Mustererkennung und Aufmerksamkeits-Algorithmen. Der Fortschritt ist so galoppierend, dass es für einen Full-Time-Job reichen würde, um überhaupt mitzubekommen, was alles Neues geschieht.
Kombination mit Workflows
Unternehmensberatungen werden nicht müde, Kosteneinsparungen und Abbau von Arbeitsplätzen als Vorteile des KI-Einsatzes zu preisen, womit wir bei der Agentic KI wären, der Verbindung Künstlicher Intelligenz mit elektronischen Workflows. Solange es sich dabei um einen Arbeitsvorgang handelte, den ein Chatbot ausführen soll, war das kein Aufreger. Geändert hat sich das mit mehrstufigen Agentensystemen. Wer um den Erhalt der Arbeisplätze besorgt ist, kann sich bisher damit trösten, dass neun von zehn Angeboten zu dieser bahnbrechenden Technik ziemlich heiße Luft sind, doch es ist beachtliche Bewegung in der Szene.
Schlussfolgerungen
Wir beschäftigen uns in diesem Abschnitt kurz mit den Leistungsgrenzen der Künstlichen Intelligenz, ihren offensichtlichen Chancen und ihren Risiken, um das Feld für erforderliche Konsequenzen abzustecken.
Realismus bitte
Angst ist kein guter Ratgeber. Unkenntnis ist eine verbreitete Quelle von Angst. Ich hoffe, mit dieser ausführlichen Darstellung, wie die Technik funktioniert, einen Beitrag geleistet zu haben für einen realistischen Blick auf die Leistungsmöglichkeiten und Leistungsgrenzen der KI-Technik.
Was die KI-Technik kann
Das Hervorstechendste aus meiner Sicht ist die Macht der Mustererkennung in Kombination mit miniaturisierbarer Technik bis zur Unsichtbarkeit, einbaubar in schier alles, was sich nicht wehrt, verbindbar mit fast allem, was high-level-digitalisiert ist. Das reicht als Stimulus für grenzenlose Phantasien. Die spannende Frage: Wollen wir das alles? Und: Wer trifft die Entscheidungen?
Was die KI-Technik nicht kann
Was Intelligenz mit Bewusstsein zu tun hat, ist nicht geklärt, insbesondere nicht, ob es Bewusstsein ohne Intelligenz gibt und umgekehrt. Wenn wir den riesigen Aufwand betrachten, den ein Sprachmodell bei der Beantwortung eines Benutzeranliegens treibt, fällt Folgendes auf:
- Digitalisierung ist Voraussetzung. Nur Digitalisiertes ist verarbeitbar. Aber Vorsicht: Die Simulation von nicht Digitalem ist digitalisierbar, zum Beispiel Emotionen. Inwieweit auch Bewusstsein simulierbar ist, bleibt noch offen.
- Keine autonome Wahrnehmung. KI-Systeme können sich keinen Input autonom beschaffen. Sie sind auf Präsentation durch Instanzen außerhalb ihrer selbst angewiesen. Sie können sich nur auf der Grundlage programmierter Instruktionen einen Input verschaffen.
- Keine autonomen Entscheidungen. KI-Systeme haben die Fähigkeit, Wahrscheinlichkeiten für alles und jedes zu bestimmen, wenn es digitalisiert ist. Die Systeme können lediglich zwischen Wahrscheinlichkeiten, die ein Algorithmus ausgerechnet hat, eine Auswahl treffen. Natürlich kann man ihnen durch Verbindung mit einem anderen Programm befehlen, eine bestimmte Auswahl auch auszuführen. Aber das hat dann jemand außerhalb des KI-Programms getan, ein Programmierer, ein Manager oder ein Politiker, der den Auftrag erteilt hat.
- Die Qualität der verfügbaren Daten setzt Grenzen. Mustererkennung ist nur so gut wie die gelernten Muster. Bisher nicht gesehene Muster erwecken die Illusion von Kreativität. Vorhersagen der Sprachmodelle beruhen nur auf bereits Vorhandenem. Was neu ist, beschränkt sich auf Kombinationen von bereits Vorhandenem oder digitalisiertem Dagewesenem.
- Riesiger Ressourcenhunger setzt Grenzen. Die Leistungen der Sprachmodelle und vergleichbarer Systeme waren nur möglich auf der Basis von Big Data und Big Money. Ihre weitere Ausdehnung und Ausbreitung ist eng an ressourcensparende technische Entwicklungen gebunden.
Diese Einschränkungen setzen den Phantasien einer künstlichen Superintelligenz so enge Grenzen, dass man von super nicht mehr reden sollte.
Nachdenktipp: zeigen

Anil Seth
Die Theorie von Wahrnehmung als kontrollierte Halluzination des britischen Kognitionswissenschaftlers Anil Seth kommt dem am nächsten, was ein Sprachmodell der Künstlichen Intelligenz tut: Es arbeitet mit Aufmerksamkeit und Wahrnehmung als kontrolllierte Auswahl aus Wahrscheinlichkeiten, und es halluziniert ständig.
Manipulationspotenziale
Es gibt wenige Untersuchungen über die technikimmanenten Manipulationspotenziale. Das größere Potenzial liegt allerdings außerhalb der Technik und ist durch den Umgang mit ihr begründet. Damit eng verbunden ist die Machtfrage: Wer bestimmt über den Einsatz welcher Technik?
Auswahlentscheidungen
Die Antworten der Sprachmodelle sind nicht „wertneutral“. Wenn man sich den Prozess der Antworterstellung eines Chatbots ansieht, gibt es mehrere Stellen, die für eine Manipulation Angriffsflächen bieten:
- Die Daten: Die Manipulationsmöglichkeit liegt in der Auswahl der Trainingsdaten für das betroffene Sprachmodell. Neben der bekannten Kritik an den üblichen BIAS sind einige neue Aspekte zu berücksichtigen: Die zunehmende Kommerzialisierung des Internet als wichtige Datenquelle für die Auswahl der Trainingsdaten und die ebenfalls zunehmende Durchdringung mit Werbung oder die Verzerrung z.B. durch Vertragsabschlüsse mit angeblichen Lieferanten für Qualitätsjournalismus (vgl. auch Stufen des Niedergangs).
- Künstlich erzeugte Daten: Immer mehr Internet-Beiträge werden durch KI erzeugt. Die Folgen sind einerseits eine zunehmende Konzentration auf bereits Dagewesenes, andererseits eine Verzerrung in Richtung des Datenmaterials und der Prompts, womit die Hersteller der KI-Inhalte gearbeitet haben.
- Das Training: Im Standard-Training lernen die Sprachmodelle statistische Korrelationen. Dabei werden soziale Stereotype zuverlässig belohnt (StereoSet), weil sie im Trainingskorpus häufig vorkommen, bekannt als sog. Likelihood-Bias.
- Bias-Amplifikation: Wenn Chat-Ergebnisse wieder als (Nach-)Trainingsmaterial verwendet werden, kommt es oft zu Verschärfungen bereits vorhandener Verzerrungen. Sie sind auch Quelle für die von vielen Chatbots vorgeschlagenen Fortsetzungs-Fragen.
- Das Vokabular des Sprachmodells: Auch hier geht es um die Wahl der Daten für die Tokenisierung bei kaum möglicher Repräsentativitäts-Prüfung der Datenauswahl. Der Einfluss auf die Ergebnisse ist schwer abzuschätzen. Bei Sprachen, die in den für die Vokabularerzeugung ausgewählten Daten unterproportional vorkommen, kann es zu Störungen bei der Erzeugung zusammengesetzter Wörter kommen, die Chatverläufe in verzerrte Richtungen führen können, bekannt als Tokenizer-Bias. Bei den derzeitigen Modellen ist die englische Sprache deutlich bevorzugt.
- Die Attention Heads des Sprachmodells: 30 bis über 100 mögliche Schichten mit je acht bis zwölf solcher Aufmerksamkeitsköpfe haben je verschiedene Algorithmen, durch die ihre Aufmerksamkeit gesteuert wird. Selbst wenn die Algorithmen bekannt wären, lässt sich ihre Wirkung auf das Ergebnis nicht abschätzen. Gleiches gilt für die Feed-Forward-Netze jeder Schicht des Sprachmodells und ihre Algorithmen.
- Mixture of Experts: Es gibt wenig Transparenz über die Art der „Experten“ in dieser Systemarchitektur und die Regeln der Router für die Auswahl der „Experten“.
- Die Wahl der Wort-Temperatur und das Sampling der Decoder: Voreinstellungen und Auswahlmöglichkeiten für Stil und Tonfall der Sprache ändern die Wahrscheinlichkeiten für das Auffinden der nächsten Token und haben wenig kalkulierbare Auswirkungen auf das Ergebnis.
- Externe Kontrollmechanismen im Decoding, bekannt als Instruction Tuning, können für die Unterdrückung oder Bevorzugung von Texten sorgen, die der Systemanbieter festlegt. Dazu gehört die Unterdrückung von politisch ungewollten oder als abwegig bewerteten Texten. Die Benutzer können mit von ihnen ungewollten Inhalten versorgt werden. Hier handelt es sich um die vermutlich stärkste Manipulationsmöglichkeit, wobei die Erzwingung von political correctness oder die main stream-Orientierung noch zu den harmlosesten Varianten gehören.
So wird deutlich, von welch unsicheren Einflussfaktoren viele Chatbot-Ergebnisse abhängen und wie verschwindend gering die Chancen für eine wirksame Kontrolle sind. Wer den main stream der Meinungsbildung beeinflussen will, findet hier viele Ansatzpunkte, womit wir wieder bei der Frage sind, wer die Verfügungsgewalt über die Technik hat.
Es ist eine gründliche wissenschaftliche Arbeit wert, die in der Technik der Sprachmodelle liegenden Verzerrungsmöglichkeiten zu untersuchen. In der auf das Phänomen der Halluzinationen fokussierten öffentlichen Diskussion spielen diese Störungen eine kaum beachtete Rolle.
Machtkonzentrationen
Die US-amerikanischen HighTech-Konzerne setzen die Rahmenbedingungen der Digitalität. Ihre Cloud-Dienste werden zum Back End von immer mehr Infrastrukturbereichen wie Telekomunikation, soziale Dienste und das Finanzwesen. Längst schicken sie sich an, auch das Front End zu übernehmen, denn mit ihren Apps darf man bezahlen, und die Banken dürfen die Transaktionen abwickeln - noch, bis die Hyperscaler deren Geschäft auch übernommen haben. Wer die Macht hat, bestimmt die Regeln. Das Gefährliche daran ist die Unsichtbarkeit: Alles geschieht ohne unsere Zustimmung, per Update oder geänderter Voreinstellungen, schleichend.
Die High-Tech-Konzerne haben die Schlüsseltechniken der Kommunikation in der Hand. Ihre Systeme sind ihr Privateigentum. Wir haben die Manipulationsmöglichkeiten beschrieben einschließlich der mit den bekannten Bordmitteln der institutionellen Bürokratie nicht mehr möglichen Kontrolle.
Außerhalb der USA ist dünnes Eis in der westlichen Welt, von Russland dürfen wir nichts wissen, China geht seine eigenen Wege. Unsere Politiker reden von digitaler Souveränität und schauen zu, wie Google mit Milliardensummen mitten in unserem Land das größte Machtzentrum einer digitalen Cloud-Infrastruktur baut. Sie lassen mit US-Amerikas Spitzentechnologie von Palantir die eigenen Bürger beobachten, so betrieben von einer schon beachtlichen Zahl von Bundesländern für ihre Polizeidienste.
Wenn selbsternannte Eliten aus der HighTech-Szene mit ein paar handverlesenen Politikern in ihrer Rolle als persönliche Akteure und den von ihnen bestimmten young global leaders meinen, anhand des Versagens nationaler Staaten debattieren zu müssen, was die Welt braucht, signalisiert das die faktische Ohnmacht, dem Recht des Stärkeren noch etwas entgegenzusetzen. Das Wort Manipulation verliert vor diesem Hintergrund seine Bedeutung.
Ausblick
Der Ruf nach Containment, der Begrenzung kritischer Entwicklungen, wird selbst seitens vieler Top-Entwickler laut. Die Geldgier der Unternehmen, die ihnen große Teile ihres Erfolges verdanken, hat sie von Bord getrieben, Paradefall OpenAI (vgl. Der Machtkampf: mission completed). Viele von ihnen haben neue Firmen gegründet, die es besser machen wollen.
 Während die US-Tech-Giganten auf immer größere Modelle, immer mehr Rechnerpower und immer mehr Big Money setzen und damit ihre ökonomische und politische Machtposition beunruhigend ausbauen, geht Chinas KI-Politik andere Wege. Die politische Führung gibt als globales Ziel vor, in zehn Jahren eine fully AI-driven society (s. Asia Times vom 20.1.2026) zu schaffen und setzt dies als Rahmen, in den sich die führenden chinesischen Firmen einzupassen haben. Sie versuchen, nicht für teuer Geld Spitzenleistungen zu erzielen, sondern Nützliches wie selbstverständlich in alle Gesellschaftsbereiche einzubauen. Die Politik setzt auf kostengünstige open source- und open weight-Modelle in einer kulturellen Logik
, die den kollektiven Nutzen, eine koordinierte Steuerung und pragmatische Problemlösungen in den Vordergrund stellt. Das macht chinesische Technik ganz besonders für den globalen Süden zunehmend attraktiv.
Während die US-Tech-Giganten auf immer größere Modelle, immer mehr Rechnerpower und immer mehr Big Money setzen und damit ihre ökonomische und politische Machtposition beunruhigend ausbauen, geht Chinas KI-Politik andere Wege. Die politische Führung gibt als globales Ziel vor, in zehn Jahren eine fully AI-driven society (s. Asia Times vom 20.1.2026) zu schaffen und setzt dies als Rahmen, in den sich die führenden chinesischen Firmen einzupassen haben. Sie versuchen, nicht für teuer Geld Spitzenleistungen zu erzielen, sondern Nützliches wie selbstverständlich in alle Gesellschaftsbereiche einzubauen. Die Politik setzt auf kostengünstige open source- und open weight-Modelle in einer kulturellen Logik
, die den kollektiven Nutzen, eine koordinierte Steuerung und pragmatische Problemlösungen in den Vordergrund stellt. Das macht chinesische Technik ganz besonders für den globalen Süden zunehmend attraktiv.
Was wir brauchen, ist nicht das Palaver der Politiker, deren Langsamkeit kein Bollwerk gegen den wachsenden digitalen Kolonialismus darstellt. Was hoffen lässt, sind die beachtlich zunehmende Initiativen auf lokalen Ebenen.
Estland gilt unter den europäischen Ländern als Vorreiter für eine eigene digitale Infrastruktur. Praktisch jeder Kontakt mit dem Staat erfolgt auf digitalem Wege, von der Teilnahme an Wahlen über die Abgabe von Steuererklärungen bis hin zum Kauf von Parktickets, heißt es auf der offiziellen Internet-Seite. Die dafür genutzte Infrastruktur X-Road ermöglicht die digitale Kommunikation zwischen Behörden, Bürgerinnen und Bürgern sowie Unternehmen.
Frankreich will bis Mitte 2026 seine nationale Gesundheits-Plattform Plateforme des Données de Santé aus Microsofts Azure-Cloud komplett herausgelöst haben (vgl. Unter Eid) und ist nun als weiteren Schritt seiner digitalen Souveränitätsstrategie dabei, Teams und andere US-amerikanische Videokonferenzsysteme (Zoom, Google Meet, Webex und GoTo Meeting) nach einjähriger Pilotphase durch eine in nationaler Regie betriebene Video-Plattform Visio (nicht zu verwechseln mit dem gleichnamigen Microsoft-Produkt) für die öffentliche Verwaltung und weitere staatliche Einrichtungen wie das Forschungszentrum CNRS zu ersetzen. Die Software basiert auf open source-Komponenten und wird in Frankreich gehostet (Quelle: heise-online vom 27.1.2026).
Großbritannien verfolgt, noch bescheiden, ähnliche Ansätze, ebenso eine wachsende Menge deutscher und europäischer Kommunen. Sie wagen Wege in die digitale Unabhängigkeit oder sind dabei, solche Schritte vorzubereiten.
Für Barcelona haben sich eine Entwickler-Community mit der lokalen Politik zusammengetan, um eine Plattform für eine öffentliche digitale Infrastruktur (Sentilo) zu bauen, ausschließlich bestückt mit open source-Komponenten (Projekt DECODE).
Auch in Deutschland regt sich etwas. Eine Reihe von Städten wie Münster, Freiburg, Schwäbisch Hall, Solingen sind dabei. Die Reihe lässt sich sicher fortsetzen, wenn man weiter recherchiert. Selbst die Bundesregierung lässt mit openCode, einer Plattform für Digitale Souveränität, zaghafte Initiativen erkennen.
Schleswig-Holsteins Landesregierung hat damit begonnen, zumindest die öffentliche Verwaltung auf eine von den US-Unternehmen unabhängige Plattform umzustellen (Schaubild zeigen).
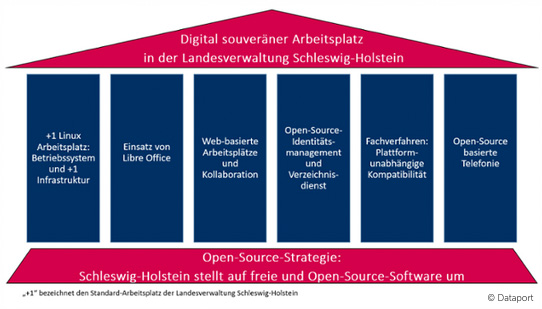
Säulen des digital souveränen Arbeitsplatzes
 Schön wäre es, wenn die Schleswig-Holsteiner, die schon mutig andere Wege gehen, für ihren lobenswerten Datenschutz elegantere Wege finden würden als die im Januar 2026 praktizierte tief im Bürokratismus versunkene Art, auf ihrer Internetseite mit einer überdimensionalen Cookie-Präsentation erst einmal die Sicht auf ihre Leistungen zu verbergen.
Schön wäre es, wenn die Schleswig-Holsteiner, die schon mutig andere Wege gehen, für ihren lobenswerten Datenschutz elegantere Wege finden würden als die im Januar 2026 praktizierte tief im Bürokratismus versunkene Art, auf ihrer Internetseite mit einer überdimensionalen Cookie-Präsentation erst einmal die Sicht auf ihre Leistungen zu verbergen.
Schaubild verbergen
Auch für Unternehmen und ihre KI-Strategien bieten sich Wege aus der Abhängigkeit von den US-Unternehmen. Sie haben längst die Möglichkeit, preisgünstig sich eigene Systeme aufzubauen (vgl. autoname Lösungen oder Kleine Chatbots mit Insiderwissen). Das ist möglich auf der Basis von open source-Produkten und sogar als on premises-Installationen.
Wenn die Politik das Anliegen digitaler Souveränität wirklich ernst nehmen will, muss sie Rahmenbedingungen für eine öffentliche Infrastrutur schaffen, die staatlichen Einrichtungen, Institutionen und Unternehmen und vor allem ihren Bürgern zugänglich ist. Vorhandene Initiativen sollten nicht als Insellösungen allein im Regen stehen gelassen werden. Kontrollierte Infrastruktur als öffentliche Dienstleistung sollte frei von Werbung und der Verpflichtung zur Gewinnmaximierung sein, beispielsweise mit den Komponenten
- Cloud-Speicherdienste ohne US-Abhängigkeit zu fairen Preisen,
- Sprachmodelle trainiert mit ausgesuchten Daten und ohne Dominanz der englischen Sprache,
- Chatbots wenn nicht europaweit dann vorzugsweise für die eigene Landessprache,
- ein werbefreier Suchindex für eine Suchmaschine,
- Schnittstellen für die Verbindung der Komponenten und ihre Integration in Anwendungssoftware,
- ...
Die Aufzählung hat keinerlei Anspruch auf Vollständigkeit, ist bestenfalls Startpunkt für ein brainstorming.
Und es muss keine zentrale Lösung sein. Lokale Autonomien sind katastrophenresilienter, auch unter Wahrung von Interkonnektivität, Interoperabilität oder wie immer man es nennen will, Verbindungen herstellen zu können.
 |
Die Chancen sind da. Es gibt die Technik für digitale Unabhängigkeit. Sie ist preiswert, und ihre Nutzung fördert den Aufbau eigener Kompetenz.
Man muss es nur ernsthaft wollen. Nicht irgendwann, sondern jetzt. |
 tse Hamburg
tse Hamburg