Lokale Autonomie und die Zukunft der Sprachmodelle
LLMs mit den meisten Parametern
| LLM | Parameter |
|---|
| GPT-4, OpenAI | 1.7-2.0 Billionen |
| PanGu-Σ, Huawei, China | um 1 Billionen |
| DeepSeek R1, DeepSeek, China | um 1 Billionen |
| PaLM, Google | 540 Milliarden |
| PaLM-2, Google | 340 Milliarden |
| LLaMA-3.1 , Meta | 405 Milliarden |
| Ernie 3.0 Titan, Baidu, China | 260 Milliarden |
| Qwen-110B, Alibaba, China | 110 Milliarden |
| Claude 3 Opus, Anthropic | >100 Milliarden |
| Mistral-8x22B, Mist1.al | 141 Milliarden |
| YaLM 100B, Yandex, Russland | >100 Milliarden |
| Yi-34B, 01.AI, China | 34 Milliarden |
Quelle: Recherche ChatGPT, Gemini 15.9.2025
Die Platzhirsche auf dem Markt der goßen Sprachmodelle (OpenAI, Google, Meta, Anthropic) haben sich einen Wettlauf um Größe geliefert: mehr Big Data, mehr Verbindungsparameter, mehr Rechnerpower. Doch sie sind nicht mehr allein, die nebenstehende Tabelle zeigt, wie schnell und gründlich die Chinesen dabei sind, ihre Rückstände aufzuholen.
Mit dem Jahr 2025 macht sich Ernüchterung breit. Die Herstellungs- und Betriebskosten steigen, das Problem mit den Halluzinationen bekommen die Anbieter nicht in den Griff, die Unternehmen sehen keinen Return on Investment.
Die großen LLMs (Large Language Models) sind Kinder der AGI, der allgemeinen generativen Intelligenz, mit dem Anspruch, alles zu wissen, was jemals irgendwo digital veröffentlicht wurde, trainiert mit allem an Daten, was sich nicht wehrt (und darüber auch mit vielen Daten, deren Autoren sich gewehrt haben).
Alternativen zu diesen Alleskönnern sind domänenspezifisch trainierte Sprachmodelle (DSLMs). Langsam setzt sich die Erkenntnis durch, dass diese Modelle präzisere Ergebnisse liefern und weit kostengünstiger sind. Das hat mehrere Gründe:
- Qualitätsverlust der Daten großer Modelle: Die Kommerzialisierung des Internets, vor allem durch die zunehmende Werbung, die Aufblähung mit immer mehr Wiederholungen und der bedenklich ansteigende Anteil von durch KI erzeugten Daten führen zu einem unvermeidlichen Qualitätsverlust. Mit je nach Thema speziell ausgewählten Datenbeständen für das Training können die kleineren Modelle einen soliden Qualitätsvorteil bieten.
- Bessere Ergebnisqualität der Spezialisten: Kleine Modelle können mit themespezifischen und durch ihre Auswahl besser qualitätsüberprüften Daten trainiert werden. Die Ergebnisse sind verlässlicher, und die Halluzinationen seltener.
- Beachtliche Kostenvorteile: Spezialisierte Modelle sind wesentlich kleiner als ihre großen Brüder, kommen mit weniger Daten aus, sind deutlich sparsamer in der benötigten Rechnerpower sowohl für das Training als auch den Betrieb, leichter nachzutrainieren und damit besser auf dem aktuellen Wissensstand zu halten.
- Reduzierte Abhängigkeit: Wer sich auf die Modelle der BigTech-Firmen einlässt, geht eine irreversible Abhängigkeit ein. Ausgerechnet die Chinesen, vorweg DeepSeek, haben es vorgemacht, abgespeckete Modelle als open source zur Verfügung zu stellen. Zahlreiche chinesische Firmen haben die erstmals 2023 von Meta erfundene und nur zögerlich verbreitete open-weight-Modelle (siehe weiter unten) in erstaunlich kurzer Zeit per Download unters Volk gebracht und damit vielen Firmen kostengünstige eigenständige Installationen ermöglicht. Domainspezifische Spezialmodelle erlauben generell mit vergleichsweise geringem Aufwand autonome Realisierungen erfolgversprechender Anwendungen.
Eine kurze Historie
Entscheidender Faktor für die günstigeren Betriebs- und Trainigskosten ist die Mixture-of-Experts-Methode (MoE) (Erklärung zeigen).
Ein Neuronales Netz besteht aus in Schichten organisierten künstlichen Neuronen, die - je nach Architektur unterschiedlich - miteinander verbunden sind. Jedes Neuron nimmt die in Zahlen umgewandelten Benutzereingaben entgegen und führt mit ihnen, gesteuert durch seine besonderen Algorithmen, Berechnungen durch. Wird dabei ein Schwellwert überschritten, „feuert“ das Neuron, d.h. es gibt den mit seinen eingebauten Regen bearbeiteten Impuls auf den Verbindungswegen zu anderen Neuronen weiter, aber verrechnet mit den im Training des Neuronalen Netzes gewonnenen Verbindungswerten (den sog. Parametern).
Die großen LLMs sind allesamt nach dem Transformer-Modell aufgebaut und haben zwischen 40 und 120 Schichten, sog. Transformer-Layers. Jede dieser Schichten hat so ungefähr zwischen 10.000 und 30.000 künstliche Neuronen. Die sog. Parameterzahl gibt an, wie viele Verbindungswerte für die Neuronen insgesamt ermittelt wurden. Diese Zahl hat bei den ganz großen Modellen inzwischen die Billionen-Marke überschritten (siehe Tabelle).
In einem klassischen LLM, einem sog. Dense-Modell, laufen die eingegebenen Daten durch alle Schichten komplett hindurch. Sie ahnen sicher, welcher Rechenaufwand dieses Verfahren verursacht. So setzen die steigenden Betriebskosten der Weiterentwicklung dieser Technik mit noch mehr Neuronen, Schichten oder Parametern ein praktisches Ende, Diagnose: drohende Unbezahlbarkeit.
Entscheidende Verbesserungen verspricht die Mixture-of-Experts-Methode (MoE). Sie ist zwar nicht neu, die Erfindung erfolgte im Rahmen einer wissenschaftlichen Pionierarbeit und wird einer Forschergruppe mit Robert Jakobs, Michael Jordan (MIT), Steven Nowlan und dem späteren Nobelpreisträger Geoffrey Hinton (Uni. Toronto) zugeschrieben, veröfffentlicht in einem Paper aus dem Jahr 1991. Der nächste wichtige Meilenstein war dann ein Paper von Google-Wissenschaftlern im Jahr 2017. Googles eigene Forschungsteams waren die ersten, die MoE in extrem großen Modellen und für Aufgaben wie maschinelle Übersetzung intern einsetzten. Die französische Firma Mistral AI hat Ende 2023 als erstes Unternehmen MoE in seinem universellen Modell Mixtral 8x7B einer breiten Öffentlichkeit und Developer-Community bekannt gemacht, bis dann Google sich seiner früheren Arbeiten erinnerte und die MoE-Technologie Anfang 2024 in sein Gemini (damals Version 1.5) wieder einbaute. Chinesische Unternehmen hatten allerdings schon wenig von der Weltöffentlichkeit beachtet 2021 eine MoE-Architektur in ein großes Sprachmodell mit 200 Milliarden Parametern (Modell PanGu-α) integriert.
Ein entscheidender Beitrag zur weltweiten Verbreitung der Methode kommt allerdings DeepSeek-V2 zu, das 2025 mit seinem im Vergleich mit den US-amerikanischen Produkten wesentlich kostengünstigeren MoE-Modell Furore machte und China fest an der Weltspitze praktischer und kommerziell relevanter KI-Produkte etablierte. Viele Varianten wurden als open source-Produkte auch mit erlaubter (allerdings eingeschränkter) kommerzieller Nutzung oder als kleinere vorbereitete open weight-Systeme mit weitgehender Veränderbarkeit der Parameter angeboten. Open weight erlaubt im Unterschied zu open source keinen Zugriff auf den Programmcode, wohl aber auf die Daten der Parameter, also den Verbindungswerten zwischen den Neuronen des Systems, mit der Konsequenz, dass man dem System ein anderes, vom Vortraining abweichendes Verhalten beibringen kann.
Für viele chinesiche Firmen, aber auch Einrichtungen vieler Entwicklungsländer war dieses Angebot in hohem Maße attraktiv, und sie haben davon in großem Umfang Gebrauch gemacht, soweit man der chinesischen Presse glauben darf. Hier hat die westliche Welt - vorsichtig formuliert - einiges verschlafen.
Die Mixture-of-Experts-Technik (MoE)
Statt einem gigantischen großen Neuronalen Netz werden bei dieser Methode mehrere kleine Experten-Netzwerke und ein übergelagertes sog. Gating-Netzwerk (oft auch Rooter genannt) verwendet. Letzters entscheidet, welche Experten-Netzwerke für die Beantwortung der Benutzeranfrage ausgewählt werden.
- Die Beutzereingabe wird in sog. Token zerlegt und nach dem berühmten (von Google erfundenen) Aufmerksamkeits-Algorithmus bewertet (Ausführlichere Erklärung zeigen).
Aus jedem Token in der ersten Schicht des Modells, der Embedding-Schicht, werden für die sog. Self Attention-Schicht drei Vektoren (query, key und value) erzeugt:
- Query fragt, wie relevant die anderen Token für den aktuell bearbeiteten Token sind.
- Key sagt, wie relevant das aktuell bearbeitete Token für andere Token sein kann.
- Value sagt, welches Ergebnis das aktuelle Token zu bieten hätte, wenn nach ihm gefragt würde.
Dem System gelingt es, mit Hilfe dieser drei pro Token erzeugten Vektoren festzustellen, welche Teilen eines Satzes die größte Aufmerksamkeit verdienen. Die Mathematik dahinter ist in natürlicher Sprache nur schwer erklärbar, aber das Ergebnis lässt sich gut beschreiben. Es wird z. B. erkannt, welches Wort das Subjekt ist, ob es auch ein Prädikat hat und welche Wörter nur Objekte sind oder nur weitere Eigenschaften beschreiben. Kurz: es lässt sich feststellen, worauf es bei einem Satz ankommt.
- Die Experten-Netzwerke sind eigenständige, oft identisch aufgebaute neuronale Netzwerke, die auf bestimmte Teilaufgaben oder Datentypen spezialisiert sind. Typischerweise handelt es sich um sog. Feed-Forward-Netzwerke, d.h. sie schicken ihre verarbeiteten Informationen nur an die nächstfolgende Schicht, also ohne Rückkopplung aus bereits absolvierten Schichten. Die einzelnen Netzwerke sind auf bestimmte Aufgaben spezialisiert, z.B. für Grammatik, Umgangssprache, Programmiercode-Syntax, wissenschaftliche Konzepte oder diverses Faktenwissen. Diese Spezialisierung wird nicht vorgegeben, sondern das gesamte System muss sie im Training selber finden. Was dabei heraus kommt, hängt entscheidend von den Trainingsdaten ab.
- Das Gating-Netzwerk (Router) liegt direkt hinter der ersten Aufmerksamkeitsschicht und ist ein kleines lineares Neuronales Netzwerk. Es berechnet für jeden Token der Benutzereingabe die Wahrscheinlichkeit eines jeden Experten für eine nützliche Antwort und wählt in der Regel nur die beiden Experten mit den höchsten Wahrscheinlichkeiten für eine brauchbare Lösung aus. Nur diese Experten werden für die weitere Bearbeitung aktiviert.
- Kombination: Die Ergebnisse der ausgewählten Experten werden gemäß ihrer Wahrscheinlichkeits-Gewichtung zu einer finalen Antwort zusammengefasst.
Die Vorteile liegen klar auf der Hand. Das Modells Mixtral 8x7B mit insgesamt 56 Milliarden Parametern zum Beispiel besteht aus acht Experten mit jeweils nur sieben Milliarden Parametern. Statt alle Experten parallel zu benutzen, wählt das Gating-Netz nur maximal zwei Experten aus. Damit wird die Rechenlast im Vergleich zu dem „dichten“ Modell von 56 Milliarden Parametern auf zwei Teilsysteme mit nur je sieben Milliarden Parametern reduziert. Man erspart das interne Durchlaufen ganz vieler Verbindungswege, was wiederum zu einem wesentlich kostengünstigeren Betrieb führt. Mit Hilfe dieser Methode lassen sich auch noch sehr große Systeme mit einigermaßen vertretbarem Aufwand betreiben. Natürlich wird auch ein bisschen herumgetrickst, damit nicht zu oft dieselben Experten ausgewählt werden. Zusätzliche Funktionen sollen für eine gleichmäßigere Auslastung sorgen. Die Betreiber solcher MoE-Systeme beteuern, dass ihr Qualitätsverlust im Vergleich zu einer Nutzung aller Parameter nur minimal sei.
Das aktuelle Wissen der Sprachmodelle hängt vom Umfang ihrer Trainingsdaten ab. Über Ereignisse nach dem Datum ihres letzten Trainings können sie aus eigener Kraft nichts wissen. Wenn sie nicht über die Fähigkeit verfügen, diese Grenzen ihres Wissens zu erkennen und nicht in der Lage sind, eine ganz normale Suchanfrage an einen oder besser gleich mehrere Betreiber einer Internet-Suchmaschine zu schicken, können sie das Ergebnis nur raten, eine der Quellen für die gefürchteten Halluzinationen. Fast alle großen Systeme sind inzwischen in der Lage, auch Internet-Suchen durchzuführen, wenn sie erkennen, dass ihr trainiertes „Wissen“ nicht ausreicht.
MoE-Systeme bieten als weiteren Vorteil größere Einfachheit beim Nachtraining, das man aufbauend auf das Vortraining auf das Training zusätzlicher Daten beschränken kann. Hier wird es für autonome Firmenlösungen besonders interessant. Als Daten für das Nachtraining kann man firmenspezifische Daten verwenden, zum Beispiel Beschreibungen von
- Produkten oder Services aus dem eigenen Angebot,
- Produktionsprozessen,
- Informationen über die Kundenstruktur und deren zeitliche Entwicklung,
- Erfahrungsberichten von Kunden,
- Empfehlungen für die Kunden, was sie mit den angebotenen Produkten unter besonderen Bedingungen anfangen können,
- Vorschriften und Regelungen, die im Umgang mit den Produkten oder Services einzuhalten sind,
- und so weiter.
Ein zusätzlicher Vorteil besteht darin, dass man bei kurz gehaltenen Intervallen für das Nachtraining ein System betreiben kann, dessen Leistung stufenweise mit der gewonnenen Erfahrung steigt, und das zu Preisen, die in Zukunft vermutlich deutlich sinken werden.
Autonome Lösungen
Mit der MoE-Technik bietet sich eine realistische Perspektive auch für kleinere Unternehmen, um aus der Abhängigkeit der großen Anbieter herauszukommen. Es werden schon eine Menge vortrainierter kleinerer Sprachmodelle als open-source- oder zumindest als open-weight-Produkte angeboten. Man kann sie herunterladen und gemäß eigenen Sicherheitsansprüchen gestalten, z.B. in einem eigenen Rechenzentrum. Bei dem relativ umfangreichen Angebot muss man allerdings darauf achten, ob es sich wirklich um open-source-Modelle oder nur um für viele Anwendungen ausreichende open-weight-Modelle handelt.
Eine wichtige Voraussetzung ist, dass man seine Daten sauber hält. Der Satz ist einfach aufgeschrieben, aber er hat es in sich. Wer unter Zeitdruck Produktbeschreibungen erstellt und sie nicht aktuell hält, wird keine Freude mit den Leistungen eines eigenen Chatbots haben. Es ist dann wie in einer Kneipe, in der jeder alles auf den Boden fallen lässt und niemand aufräumt. Es dauert dann nicht lange, und man befindet sich buchstäblich auf einer elektronischen Müllhalde.
Die Chancen für firmenspezifische Systeme werden noch interessanter, wenn man die Möglichkeiten betrachtet, die das von Anthropic entwickelte Model Context Protocol (MCP) bietet. Dabei handelt es sich um den Vorschlag einer standardisierten Schnittstelle, über die Sprachmodelle mit externen Datenquellen, Tools und Systemen interagieren können (Details erklären).
Die wichtigsten Funktionen der MCP-Schnittstelle:
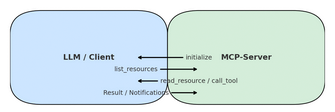 Mit MCP verbundene Systeme
Auf Bild klicken für Größe ändern
Mit MCP verbundene Systeme
Auf Bild klicken für Größe ändern
- Standardisierung: Statt für jedes Modell und jede Datenquelle eine eigene Verbindungslogik programmieren zu müssen, erlaubt MCP die Nutzung einer einheitlichen Schnittstelle.
- Zwei-Wege-Kommunikation: Ein KI-Programm kann nicht nur Abfragen tätigen, sondern auch Antworten von anderen Systemen erhalten und über das Protokoll definierte Aktionen (in Sinne der Agenten-Technik) durchführen.
- Aktualität: Bei guter Pflege der Datenquellen kann man ohne großen Aufwand die Leistung eines Systems aktuell hakten, das über MCP mit anderen Systemen verbunden ist; Daten können abgefragt werden und müssen nicht "erraten" werden.
- Verlässlichkeit: Da man als Unternehmen die volle Kontrolle über die Daten hat, kann man das Risiko für Halluzinationen deutlich senken.
- Mitgelieferte Werkzeuge: Die MCP-Schnittstelle stellt Software Development Kits (SDK) für gängige Programmiersprachen zur Verfügung. Für viele Datenbanken und andere Systeme gibt es ebenfalls APIs.
Es lohnt sich, diese Entwicklung im Auge zu behalten.
Mogelpackungen
Die großen Chatbot-Betreiber (OpenAI, Google, Anthropic) bieten selbstverständlich MCP an, allein schon um ihre KI-Agenten-Konzepte weiterzutreiben. Aber auch die Cloud-Plattformanbieter schlafen nicht, z.B. Amazon Web Services, Google Cloud Platform, Microsoft Azure und Cloudflare. Selbst SAP hat sich entschieden, ausgerechnet mit OpenAI eine entsprechende Entwicklungsumgebung auf in Deutschland stationierten Servern anzubieten, mit dem finanziellen Segen der deutschen Bundesregierung. Unternehmensberatungen sind ebenfalls dabei, die Trittbretter des neuen Zugs zu erobern, und sei es auch nur, um sich als Trusted Advisor für regulatorische Fragen in der bürokratieverliebten Europäischen Union anzubieten.
Die beschriebenen Services sind leider nicht frei von Wehrmutstropfen:
- Wegen des Cloud Act gibt keine hundertprozentige Sicherheit vor dem Zugriff US-amerikanischer Behörden (und den Spontaneinfällen von Donald Trump).
- Die Abhängigkeit von den großen US-amerikanischen Firmen wird weiter zementiert.
Perspektiven
Das MCP-Konzept ist noch neu. Viele Unternehmen fühlen sich durch die hohen Versprechungen der KI-Anbieter verunsichert, weil die Returns on investment meist noch mit der Lupe gesucht werden müssen. Eigene Sprachmodelle zu entwicklen und zu trainieren ist zu teuer. Bei den Open Sorce-Angeboten steht das Signal eher auf Gelb: Warten, bis sich die Spreu vom Weizen getrennt hat.
Alles nicht so tragisch: Wenn sich MCP wirklich durchsetzt, ist es kein großes Abenteuer, auch noch später ein anfänglich ausgewähltes Basis-LLM durch ein anderes zu ersetzen. Auf jeden Fall kann man mittelfristig die Rahmenbedingungen schaffen, um sich von den US-amerikanischen BigTech-Giganten unabhängig zu machen.
 tse Hamburg
tse Hamburg