Translate


Qualitätsprobleme der KI-Modelle

Quelle:KS & ChatGPT 4.o
Hinter jedem Chatbot steckt ein Large Language Model (LLM), und das muss trainiert werden. Will man eine Antwort auf die Frage, warum die Leistungen der Chatbots sich seit Anfang 2025 mit zunehmenden Halluzinationen verschlechtern, so liegt es nahe, sich zunächst ihr Training näher anzusehen. Danach ist ein Blick auf die veränderte Datenqualität des Internets angesagt.
Das Training der Sprachmodelle
Der Goldstandard des Trainings der KI-Modelle besteht immer noch darin, dass man eine noch tolerierbare Fehlergröße vorgibt und das Modell so lange trainiert, bis diese Fehlerquelle unterschritten wird. Gemessen wird dies mit Hilfe einer Lernkurve für die ausgewählte Trainingsmethode.
Die Lernkurve gibt die Entwicklung der Fehler in Abhängigkeit von der Anzahl der Trainingsschritte wieder. Unter Fehler wird in diesem Fall die Abweichung des vom System gelieferten Ergebnisses von den "richtigen" Antworten beim Training mit ausgewählten Trainingsdaten verstanden.
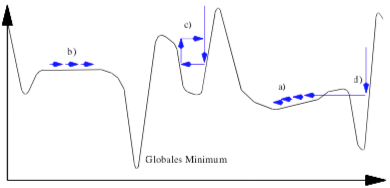
Mögliche Verläufe einer Fehlerkurve beim Training eines
Large Language Models
Die X-Achse zeigt die Anzahl der Trainingsschritte, die Y-Achse den als Fehlerquote definierten Wert der Lernkurve.
Quelle: David Kriesel: Ein kleiner Überblick über Neuronale Netze, S. 66
Ausschlaggebend für die Beurteilung des Trainings ist dabei die Veränderung des Fehlers bei jedem Trainingsschritt (Mathematisch wird dies als Gradient der Fehlerfunktion beschrieben).
Man macht dabei die seltsame Erfahrung, dass es Situationen gibt, in denen sich dieser Gradient nicht ändert, also keine Verbesserung erreicht wird. Im obigen Diagramm ist diese Situation als b) markiert. Man weiß beim realen Training jetzt nicht, wie es weiter geht, weil man die Fehlerkurve vorab nicht kennt. Man hat bei größerer Anzahl der Trainingsschritte möglicherweise keinen Erfolg. Auch bei weniger Trainingsschritten ändert sich nichts am Ergebnis. Wenn man zu große Schritte macht, kann es passieren, dass man das "Fehlertal" der als "Globales Mininimum" bezeichneten Situation überspringt und bei Fortsetzung des Trainings mit mehr Schritten wieder schlechtere Ergebnisse erhält.
Ärgerlich ist die mit c) bezeichnete Situaton. Hier kann es passieren, dass man bei mehr Trainingsschritten eine Verbesserung oder eine Verschlechterung erreicht, je nachdem auf welcher Seite des (unentdeckten) Tals man sich befindet. Wenn man Pech hat und nicht die richtigen Trainingsschrittgröße wählt, kann es dabei bleiben, dass man buchstäblich auf der Stelle tritt.
Ebenfalls ungünstig ist die als a) markierte Stelle. Und die als d) markierte Situation ist ganz besonders ärgerlich. Auf der linken "Uferseite" der Kurve ist man wegen der schnellen Erfolge bei zusätzlichen Trainingsschritten geneigt, zu große Schritte zu machen und hat dann das Tal für eine Fehlerminimum überschritten.
Es gibt sehr unterschiedliche Verfahren für die Fehlerbehandlung beim Training von KI-Modellen. Vor allem gibt es kein analytisches Verfahren, mit dessen Hilfe man den exakten Verlauf des Fehlerverhaltens vorhersagen könnte, man muss alles ausprobieren und durch Erfahrung herausfinden.
Die Fehlerfunktionen (Loss Functions) bestimmen, wann ein Training abgebrochen werden kann. Die Optimierung dieser Funktionen ist eine Wissenschaft für sich uns stellt die Forschung vor ähnliche Probleme, wie man sie aus der Verhaltensforschung der Sozialwissenschaften kennt.
Fazit: Das Trainingsverfahren selbst führt zu noch nicht abschließend geklärten Auswirkungen auf die Qualität der Ergebnisse.
Veränderte Datenqualität
Das Absinken der Qualität lässt sich nicht allein mit den Ungewissheiten des Trainingsverfahrens erklären. Wie bei allen mathematischen Modellen darf man der Versuchung nicht erliegen, zu glauben, dass es eine Übereinstimmung zwischen mathematischem Modell und Realität geben muss.
Inflation der Daten
Die Realität ist in diesem Fall geprägt durch die ungeheuer große Menge der Trainingsdaten, die Texte allmöglicher Art enthält, seriöse wissenschaftliche Werke, Feuilletonbeiträge, Small Talk-Fetzen bis zu den Posts aus den social media, Esoterik oder ganz einfach Klatsch und Tratsch, auch böswillige Texte, unkontrolliert häufig kopierte Sachen mit ähnlichem bis identischem Inhalt und neuerdings auch zunehmend künstlich erzeugte Texte. Seit Beginn des Internets hat es eine deutliche Verschiebung der Inhaltsschwerpunkte durch die Kommerzialisierung gegeben. Einem Gerücht zufolgen sollen bereits 30 Prozent der Wikipedia-Einträge von KI erzeugt sein (Sommer 2025).
Künstlich erzeugte Inhalte und Werbelastigkeit
Die zentrale Sorge lautet: Wenn immer mehr Inhalte im Internet nicht mehr primär informativ, sondern SEO-optimiert, kommerziell oder durch KI-Programme produziert sind, hat das direkte Auswirkungen auf die Trainingsgrundlagen – und damit auf deren Antwortqualität, Vielfalt und Wahrhaftigkeit. Wenn das Web immer mehr mit generierten oder durch Werbung motivierten Inhalten überflutet wird, sinkt der Informationsgehalt, und die Modelle lernen weniger nützliche, weniger diverse und weniger korrekte Inhalte. Diese Verschmutzung des Web ist bereits als Content Drift bekannt.
Suchmaschinen- und Empfehlungsalgorithmen führen dazu, dass Inhalte oft nicht nach Relevanz, sondern nach kommerziellem Nutzen geschrieben werden.
„The more the web is optimized for monetization, the less useful it becomes as a knowledge base for AI.“
Je mehr das Internet für die Monetarisierung optimiert wird, desto unbrauchbarer wird es als Wissensbasis für KI.
schreiben Minyue Zang e.a in ihrer Studie "Artificial intelligence and the future of communication sciences and disorders" aus dem Jahr 2024.
Fazit
Wenn generative Modelle zunehmend auch die Inhalte produzieren, auf denen neue Modelle trainiert werden, entsteht ein „model collapse“ – die Vielfalt und Tiefe der Information nimmt ab.
 Keine rosigen Zeiten für die Zukunft des Internet.
Keine rosigen Zeiten für die Zukunft des Internet.
Die weitere Entwicklung braucht dringend ein containment. Doch keine Agentur in Sichtweite, die das bewegen kann. business first eben.
Quality problems of AI models
Dependence of the training quality of a language model on the frequency of the training steps.
Quelle:KS & ChatGPT 4.o
Behind every chatbot is a large language model (LLM), and this needs to be trained. If you want an answer to the question of why the performance of chatbots has deteriorated since the beginning of 2025 with increasing hallucinations, it makes sense to first take a closer look at their training.
Training the language mode
The gold standard for training AI models is still to specify a tolerable level of error and train the model until the error falls below this level. This is measured using a learning curve for the selected training method.
The learning curve shows the development of errors as a function of the number of training steps. In this case, error means the deviation of the result provided by the system from the 'correct' answers when training with selected training data.
Possible progressions of an error curve when training a large language model
Die X-Achse zeigt die Anzahl der Trainingsschritte, die Y-Achse den als Fehlerquote definierten Wert der Lernkurve.
Source: David Kriesel: A brief overview of neural networks, p. 66
The decisive factor for assessing the training is the change in the error at each training step (mathematically, this is described as the gradient of the error function).
We have the strange experience that there are situations in which this gradient does not change, i.e. no improvement is achieved. In the diagram above, this situation is marked as b). In real training, you don't know what will happen next because you don't know the error curve in advance. You may not be successful with a larger number of training steps. Even fewer training steps will not change the result. If you take too many steps, it can happen that you skip the 'error valley' of the situation known as the 'global minimum' and get worse results again if you continue training with more steps.
The situation labelled c) is annoying. Here it can happen that you achieve an improvement or a deterioration with more training steps, depending on which side of the (undiscovered) valley you are on. If you're unlucky and don't choose the right training step size, you may end up literally treading water.
The point marked as a) is also unfavourable. And the situation marked as d) is particularly annoying. On the left 'bank' of the curve, you are inclined to take too large steps due to the rapid success of additional training steps and have then crossed the valley for an error minimum.
There are very different methods for error handling when training AI models. Above all, there is no analytical procedure that can be used to predict the exact course of the error behaviour; everything has to be tried out and discovered through experience.
Conclusion: The training procedure leads to unclear effects on the quality of the results
Changed data quality
The drop in quality cannot be explained solely by the uncertainties of the training procedure. As with all mathematical models, one must not succumb to the temptation to believe that there must be a correspondence between the mathematical model and reality.
Inflation of data
In this case, reality is characterised by the enormous amount of training data, which contains texts of all kinds, serious scientific works, feature articles, small talk snippets and posts from social media, esotericism or simply gossip and malicious texts, uncontrollably copied items with similar or identical content and, more recently, increasingly artificially generated texts. Since the beginning of the Internet, there has been a clear shift in the focus of content due to commercialisation. According to one rumour, 30 percent of Wikipedia entries are already generated by AI (summer 2025).
Artificially generated content and heavy advertising
The main concern is that if more and more content on the internet is no longer primarily informative, but SEO-optimised, commercial or produced by AI programmes, this will have a direct impact on the basis for training - and therefore on the quality of the answers, diversity and veracity. If the web is increasingly flooded with generated content or content motivated by advertising, the information content decreases and the models learn less useful, less diverse and less correct content. This pollution of the web is already known as content drift.
Search engine and recommendation algorithms mean that content is often written for commercial benefit rather than relevance.
„The more the web is optimized for monetization, the less useful it becomes as a knowledge base for AI“
write Minyue Zang e.a. in their study 'Artificial intelligence and the future of communication sciences and disorders' from 2024.
Conclusion
If generative models increasingly produce the content on which new models are trained, a 'model collapse' occurs - the diversity and depth of information decreases.
These are not rosy times for the future of the Internet..
Further development urgently needs containment. But there is no agency in sight that can make this happen - business first.
Translate

 tse Hamburg
tse Hamburg