Verstehen und Bedeutung - was versteht die Künstliche Intelligenz?
Wir gehen davon aus, dass Dinge, die wir verstehen, eine Bedeutung haben. Dieser Beitrag will ausloten, was Bedeutung für Maschinen - speziell Computer - ist und wie es um ihre Fähigkeit bestellt ist, auch zu verstehen, was sie tun. Antworten auf diese Frage sind angebracht, wenn man sich mit den aktuell wieder beflügelten Phantasien um die angeblich kurz vor ihrem Durchbruch stehende Superintelligenz auseinandersetzen will oder muss.
Mit „nachdenken“ meldet sich etwas nassforsch die Chatbot-App von OpenAI auf dem SmartPhone, wenn man ihr eine Frage stellt. Doch nicht nur sprachlich machen die Baupläne der Neuronalen Netze und der Large Language Models - Spitze der heutigen KI-Technik - Anleihen beim menschlichen Gehirn.
Die KI-Technik versucht nachzubauen, wie man Dingen Bedeutung zuordnen kann. Der Versuch, Bedeutung zu messen, ist genauso alt wie die Geschichte der Künstlichen Intelligenz, für deren Start meist das Dartmouth Summer Reseach-Projekt von 1956 angesehen wird.
 Im Jahr darauf, 1957, erschien das Buch The Measurement of Meaning des amerikanischen Psychologen Charles Osgood und begründete eine lange Tradition von Versuchen, Bedeutung zu messen. Zentraler Begriff dabei ist der Semantische Raum, ein mathematisches Modell, in dem die Bedeutung aller Dinge, Personen, Begriffe und Ereignisse durch Vektoren verortet wird. Hierauf zurück gehen die heute noch in der behavioristischen Psychologie und der Werbeforschung bekannten Polaritätenprofile.
Im Jahr darauf, 1957, erschien das Buch The Measurement of Meaning des amerikanischen Psychologen Charles Osgood und begründete eine lange Tradition von Versuchen, Bedeutung zu messen. Zentraler Begriff dabei ist der Semantische Raum, ein mathematisches Modell, in dem die Bedeutung aller Dinge, Personen, Begriffe und Ereignisse durch Vektoren verortet wird. Hierauf zurück gehen die heute noch in der behavioristischen Psychologie und der Werbeforschung bekannten Polaritätenprofile.
Das Messen von Bedeutung
Kann man Bedeutung wirklich messen?
- Die schlechte Nachricht: Nicht wirklich.
- Die gute Nachricht: Aber die Beziehungen von Bedeutungen untereinander.
Bedeutungen werden bei diesen Messversuchen im wesentlichen durch Beziehungen dargestellt. Es geht nicht um die Inhalte des Verstehens, sondern um die Beziehungen einer Bedeutung zu den vielen anderen Bedeutungen.
Collins English Dictionary, second edition 1986
Intelligence: 1. the capacity to understanding; ability to perceive and comprehend meaning. 2. good mental capacity: a person of intelligence. 3. old-fashioned news; information. 4. military information of enemies, spies etc. 5. a group of department that gathers or deals with such information. 6. (often cap.) an intelligent beeing, esp. one that is not embodied. 7. (modifier) of or relating to intelligence: an intelligent network. [from latin intelligentia, from intellegere to discern, comprehend, literally: choose between, from INTER + legere to choose]
Intelligenz: 1. die Fähigkeit zu verstehen; die Fähigkeit, Bedeutungen wahrzunehmen und zu begreifen. 2. gute geistige Fähigkeiten: eine Person mit Intelligenz. 3. altmodische Nachrichten; Informationen. 4. militärische Informationen über Feinde, Spione usw. 5. eine Gruppe von Abteilungen, die solche Informationen sammelt oder sich damit befasst. 6. (oft cap.) ein intelligentes Lebewesen, besonders eines, das nicht verkörpert ist. 7. (Modifikator) von oder in Bezug auf Intelligenz: ein intelligentes Netzwerk. [von lateinisch intelligentia, von intellegere erkennen, begreifen, wörtlich: wählen zwischen, von INTER + legere wählen]
Ähnlich wie in einem Dictionary, nebenstehend am Beispiel des Wortes Intelligence aus dem Collins English Dictionary: Das Wort wird durch andere Wörter und Beschreibungen mit Referenzen auf andere Wörter erklärt, im wesentlichen also durch Beziehungen zu anderen Bedeutungen. Dieses Verfahren schreckt auch nicht vor Selbstreferenzen zurück, also durch sich beziehen auf sich selbst mit zusätzlichen Erklärungen (siehe nebenan).
Diese Grundidee finden wir wieder in den Bauplänen der KI-Sprachmodelle. Alles nicht wirklich neu.
In Anlehnung an Osgood's Semantisches Differential, wie die Polaritätenprofile auch genannt werden, kann man die Bedeutung eines Wortes durch seine Beziehungen zu anderen Wörtern beschreiben. Mit dieser sehr eingeschränkten Methode wird ein zu testender Begriff auf einer Skala mit ein paar Dutzend Items gegenseitiger Testbegriffe wie hell-dunkel, warm-kalt, positiv-negativ, jung-alt usw. bewertet. Diese Items enthalten jeweils drei Abstufungen in jede Richtung.
Beispiel eines Items aus einem Polaritätenprofil
Man kann dann die Bedeutung beliebiger Begriffe mit Hilfe einer solchen Skala erfassen. Die Skala besteht meist aus 30 solcher polaren Items. In dem abgebildeten Beispiel ist der zu vermessende Begriff auf dem Item warm-kalt der Profil-Skala angekreuzt. Das Verfahren sieht vor, eine Gruppe von Testpersonen solche Polaritätenprofile für die zu testenden Begriffe ausfüllen zu lassen. Die Ergebnisse werden dann in einen großen Datentopf geworfen, miteinander korreliert und ausgewertet.
Durch die Brille der Mathematik betrachtet spannt das Messinstrument aus den 30 polaren Items einen Vektorraum mit 30 Dimensionen auf. Jedes einzelne Item der Skala wird durch einen solchen Vektor repräsentiert. Anschaulich schaffen wir es noch gut, uns einen dreidimensionalen Raum vorzustellen, aber mit mehr Dimensionen wird es dann schnell schwieriger - für die Mathematik aber kein Problem.
In dem Modell werden Abhängigkeiten durch Korrelationen beschrieben, Zahlen zwischen -1 und +1. Beträgt die Korrelation von zwei Merkmalen -1, dann kommen sie nie gemeinsam vor. Bei +1 kommen sie ausnahmslos gemeinsam vor. Der Wert 0 bedeutet, dass es keinen Zusammenhang für das gemeinsame Vorkommen der Merkmale gibt, alles also zufällig ist, oder anders gesagt: zwischen beiden Merkmalen gibt es keinen erkennbaren Zusammenhang. Meistens kommen allerdings Werte zwischen diesen Grenzen +1 und -1 vor, was dem Sachverhalt entspricht, dass Dinge oft nur teilweise gemeinsam vorkommen oder sich ausschließen.
Geometrisch dargestellt zeigen bei positiver Korrelation die Vektor-Pfeile der betroffenen Merkmale in eine ähnliche Richtung, bei negativer Korrelation in entgegengesetzte Richtungen, und bei Null Korrelation stehen sie senkrecht aufeinander. Wenn man das Verfahren des Semantischen Differenzials genau nimmt, lässt es sich noch weiter verfeinern. erklären
In Osgoods Semantischem Differenzial werden die polaren Begriffe des Test-Instruments warm-kalt, hell-dunkel usw. so behandelt, als ob sie untereinander unabhängig wären. Das ist natürlich nicht der Fall. Diese internen Abhängigkeiten der Merkmale untereinander kann man ermitteln, wenn man die einzelnen Begriffe der Skala ebenfalls mit Hilfe der Skala testet. Wenn hell-dunkel nicht völlig unabhängig von warm-kalt ist, bedeutet das im Semantischen Modell, dass die Vektoren der Begriffe nicht senkrecht aufeinender stehen, sondern schiefe Winkel zueinender bilden. Das Ergebnis ist dann ein schiefwinkliges Koordinatensystem der 30 Verktoren. In diesem System lässt sich der gestestete Begriff dann abbilden.
Mit statistischen Methoden, z.B. der Faktoranalyse, lassen sich - vereinfacht ausgedrückt - die 30 Vektordimensionen auf eine geringere Anzahl reduzieren. In dem in der nachfolgenden Abbildung gezeigten Beispiel wurden in einem Experiment aus dem Sommer 1972 in einer kleinen Gruppe von Studierenden verschiedene Begriffe (wie Liebe, Hass, Macht, Universität) mit einem solchen Polaritätenprofil getestet und mit einem faktoranalytischen Verfahren ausgewertet. Die Abbildung zeigt die drei wichtigsten Dimensionen, die in der Abbildung als Affektivität, Stabilität und Aktivität interpretiert und so bezeichnet wurden. Dem Modell ist die Benennung völlig egal, es ist nur an den Beziehungen der Begriffsdarstellungen untereinander interessiert.
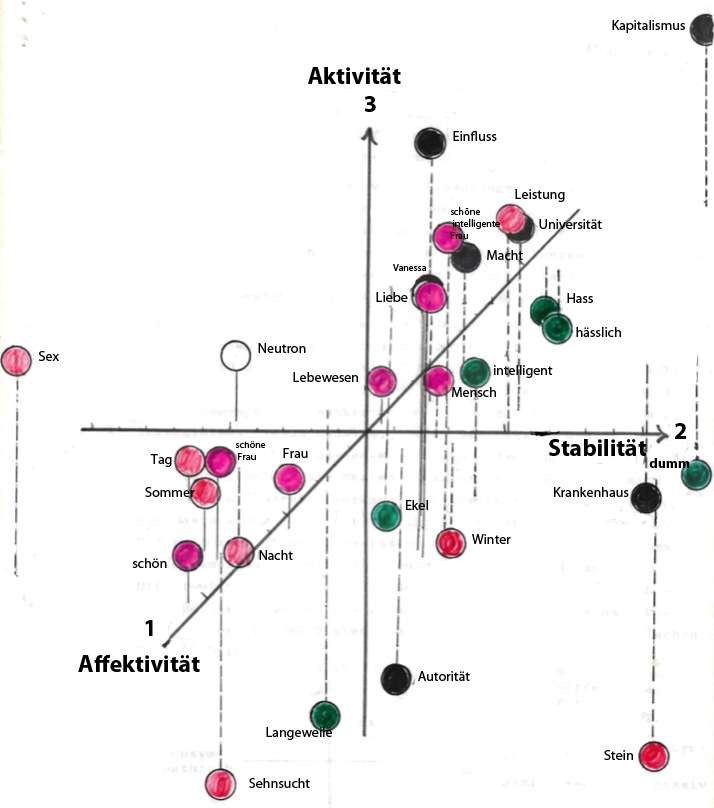
Darstellung der ersten drei Dimensionen eines Semantischen Raumes
für in einer kleinen Grppe getestete Begriffe
Quelle: Karl Schmitz, Entwicklung eines operationalen Konzepts zur Messung von Bedeutung, Hamburg 1972
Es ist nicht gerade anschaulich, drei Dimensionen auf einer nur zweidimensionalen Ebene darzustellen. In der Abbildung wird versucht, die drei berechneten Vektoren Affinität, Stabilität und Aktivität geometrisch darzustellen. Der erste Vektor Affinität zeigt aus der Abbildung heraus, der zweite Vektor Stabilität bildet die links-rechts-Richtung und der dritte Vektor Aktivität die unten-oben-Richtung. Die einzelnen getesteten Begriffe sind als kleine Ballons in diesem Koordinatensystem dargestellt. Der Fußpunkt der gestrichelten Linien zeigt den Wert der getesteten Begriffe in der Affektivität-Stabilität-Ebene. Die Länge der gestrichelten Linie entspricht dem Wert für die Aktivität. Links bzw. unten steht für negative, rechts bzw. oben für positive Werte. Alles ist schön auf ±1 normiert, sodass die Werte die Korrelationen der getesteten Begriffe mit den genannten künstlichen Dimensionen des Vektorraums darstellen. So wird beispielsweise dem getesteten Begriff Neutron null Affektivität, ein bisschen Aktivität aber seltsamerweise eher leichte Instabilität beigemessen - Nun ja, die Studenten (keine Physiker!) im Jahre 1972 sahen das so. Der Begriff Universität dagegen wurde deutlich in die Nähe von Aktivität und Stabilität gerückt, aber Null Affektivität - waren wohl alles emontionsgebremste fleißige Studierende.
Warum macht man das alles? Ganz einfach, nur um damit rechnen zu können. Bedeutungsunterschiede werden durch den Abstand der Vektor-Endpunkte voneinander dargestellt. Je näher die Vektoren beieinander liegen, desto ähnlicher sind die Bedeutungen, die sie repräsentieren, so die Interpretation des Modells. Nun endlich kann man damit machen, was Computer gut können, nämlich rechnen.
Mit Zahlen kann man gut umgehen, Meinungen in den Köpfen der Menschen sind da etwas schwieriger zu handhaben. Warum das wichtig ist, sehen wir, wenn wir jetzt die Instrumente der Künstlichen Intelligenz betrachten.
Willkommen in der virtuellen Welt: Der Vektorraum der großen Sprachmodelle
Schauen wir uns zunächst die Large Language Models an, die den heute Furore machenden Chatbots zugrunde liegen. Der Unterschied ist, dass wir es jetzt nicht mehr mit nur ein paar Dutzend Studierenden zu tun haben, deren Input mit einem Testinstrument aus 30 polaren Begriffen verortet wurde. Das Testinstrument der LLMs besteht aus den Daten eines riesig großen Datenbestandes aus der Big Data-Welt. Wir haben Millionen, Milliarden oder Billionen von Wörtern und deren Abhängigkeiten untereinander. Abhängigkeit heißt für die Modelle gemeinsames Vorkommen in den vielen Texten dieses Big-Data-Universums.
Die für den Aufbau eines solchen KI-Sprachmodells benutzte Software, meist eines der vielen Typen von Neuronalen Netzen, „weiß“ zunächst gar nichts. Sie muss erst trainiert werden. Wer ein solches Modell selber aufbauen will, muss folgendes tun:
- Software-Auswahl: Aus dem inzwischen großen Software- Angebot muss eine für den späteren Hauptverwendungszweck geeignete Software ausgewählt werden, viele technische Details, z.B. welches Neuronale Netz, welche Netztopologie, wieviele Neurone, wie viele verborgene Schichten usw. Man muss sich entscheiden, ob man ein öffentliches Modell aus einem Cloud-Angebot der großen Anbieter (OpenAI bzw. Microsoft, Google, Meta usw.) nimmt, lieber eine private Cloud nutzen oder ein solches Instrument on premise, also auf eigenen Servern des Unternehmens installieren will. Man kann sich für ein schon vortrainiertes Modell entscheiden, oder wenn man viel Geld hat alles selber bewerkstelligen.
- Vortrainierte Modelle: Die meisten Unternehmen entscheiden sich für diesen Weg. Dann hat der Anbieter für sie bereits die folgenden Aufgaben erledigt:
- Daten-Auswahl: Eine geeignete Testdatenmenge aus den riesigen verfügbaren Datenbeständen ist für das Training des Systems ausgewählt bzw. zusammengestellt worden - eine wichtige Entscheidung, die über den Umfang und die Qualität des später für verlässlich erachteten Wissens des Systems entscheidet.
- Cleaning und Filterung: Die ausgewählten Daten werden von für unbrauchbar erachteten Datensätzen gereinigt, sozusagen von Datenmüll befreit. Was hier ausgesiebt wird, ist später nicht mehr da.
- Tokenizing - ein schlicht nicht übersetzbarer Begriff: Die Wörter des Datenbestandes werden in sog. Token zerlegt, d.h. so bearbeitet, dass nur die Wort- oder Bedeutungswurzeln übrig bleiben. Aus Wörtern wie sang, gesungen oder singen wird z.B. nur sing als Wortstamm herausgefiltert. Es gibt eine Menge von spezieller Software, die das kann. Die so erzeugten Token sollen später für beliebige Zusammensetzungen brauchbar sein. Was jetzt übrig bleibt, bildet das Vokabular des Systems.
- Vektorisierung: Die einzelnem Wörter und Wortkombinationen werden als Vektoren dargestellt. Für die mathematische Behandlung spielt es dabei keine Rolle, ob es sich um Millionen oder Milliarden Dimensionen des durch die Vektoren aufgespannten Raumes handelt. Wichtig ist nur zu wissen, dass Begriffe oder Dinge mit benachbarten Bedeutungen in diesem künstlichen Raum auch nahe beeinander liegen. Diese Abstände der Vektoren kann man genau messen. Deshalb sind sie für Computer gut verdaubar.
- Training: Jetzt werden Wortpaare oder ganze Wortumgebungen gesucht (sog. embeddings). Das Vokabular wird in sehr häufigen Trainingsstufen durchsucht, um festzustellen, welche Wortkombinationen mit welcher Häufigkeit in dem gigantischen Wortvorrat vorkommen. Bei jedem Trainings-Durchlauf werden die Verbindungsgewichte der Neurone des Systems gemäß einem Fehlerkorrekturverfahren ein klein wenig geändert. Das Training wird dann als erfolgreich beendet, wenn die Ergebnisse der Trainings-Durchläufe unterhalb eine vorgegebene Fehlerrate gesunken sind. Wird ein Modell sozusagen von der Picke auf trainiert, so sind das schon einmal gerne ein paar Milliarden Trainingsschritte, verständlich, dass sich ein solcher Prozess nur hochautomatisiert durchführen lässt. Das Training ist eine sehr komplexe Angelegenheit.
- Spezielle Algorithmen stehen für spezielle Benutzeranfragen oder Aufgaben zur Verfügung. Nehmen wir das relativ einfache Beispiel eines Übersetzungsprogramms. Zu den Wörtern der Benutzereingabe werden die wahrscheinlichsten Wörter unter Berücksichtigung der Wortumgebungen in der anderen Sprache gesucht. Um sie zu finden müssen die Vektoren herhalten.
- Spezialisierung: Hat man sich für ein bereits vortrainiertes Modell entschieden, so erspart man sich die Arbeit der eben beschriebenen Schritte. Man kann das Modell jetzt für die besonderen Belange des Unternehmens spezialisieren und wählt unter diesem Gesichtspunkt zusätzliche Daten für eine Art „Aufbautraining“ aus, auch Finetuning genannt. Diese Daten werden bereinigt, tokenisiert, vektorisiert und nachtrainiert - im Vergleich zum Basistraining ein überschaubarer Aufwand.
Technisch läuft das Verfahren etwas komplizierter ab:
Das System ordnet jedem Wort zunächst einen Bedeutungsvektor zu; der zeigt auf einen Ort in dem künstlichen Semantischen Raum, den das System für seinen gesamten „Wortschatz“angelegt hat. Mit Hilfe eines besonderen Algorithmus werden diejenigen Wörter herausgefunden, die mit höchster Wahrscheinlichkeit kurz vor oder nach dem betroffenen Wort, also in seiner Nachbarschaft vorkommen. Außerdem bekommt das Wort zwei weitere „Hilfsvektoren“", die mit key und mit query bezeichnet werden. Ihr Sinn besteht darin, dass das System für das gerade behandelte Wort überprüfen kann, mit welchen anderen Wörtern es am stärksten gekoppelt ist. Gesucht werden die Wörter, deren Key-Vektoren zu einem Ort zeigen, der möglichst nah an dem Ort liegt, auf den der Query-Vektor des gerade bearbeiteten Wortes zeigt. Das System führt sozusagen Buch über die wichtigsten auf diese Weise gefundenen Wahrscheinlichkeiten. Diese Methode ist durch das Transformer-Verfahren mit der Einführung eines „Aufmerksamkeits-Mechanismus“ erheblich verbessert worden. Wenn das System die Benutzeranfrage „verstanden“ hat, wird die Antwort Wort für Wort aufgebaut.
Die Leistungsfähigkeit der Systeme hängt nicht nur vom Tainingsdatenbestand und dem Training ab, sondern hat auch strukturelle Grenzen, die in der Wahl der Netzwerktopologie begründet sind,
- der Anzahl der verborgenen inneren Neuronenschichten,
- der Anzahl der Neurone insgesamt sowie per Schicht,
- der Art, dem Umfang und den Werten (sog. Parametern) der Verbindungen unter den Neuronen und
- den Leistungen der spezialisierten Aktivierungs- und Propagierungsfunktionen der Neuronen.
Mensch und Maschine: Die Unterschiede
Wie unser Gehirn mit Bedeutungen umgeht - in computerfreundlichem Jargon würde man sagen: wie es Bedeutungen codiert - ist uns bestenfalls ahnungsweise bekannt. Jedenfalls entstehen sie nicht durch Trial-and-Error-Verfahren wie beim Training der Large Language-Modelle, sondern durch Lernen und Erfahrung im realen Leben.
Der Input für unser Gehirn ist nicht auf digitalisierte „Token“, Wörter, Bilder oder Töne beschränkt, sondern bedient sich aller fünf Sinne, über die wir verfügen. Dabei spielen Gefühle eine wichtige, wenn nicht entscheidende Rolle. Da müssen Computer passen.
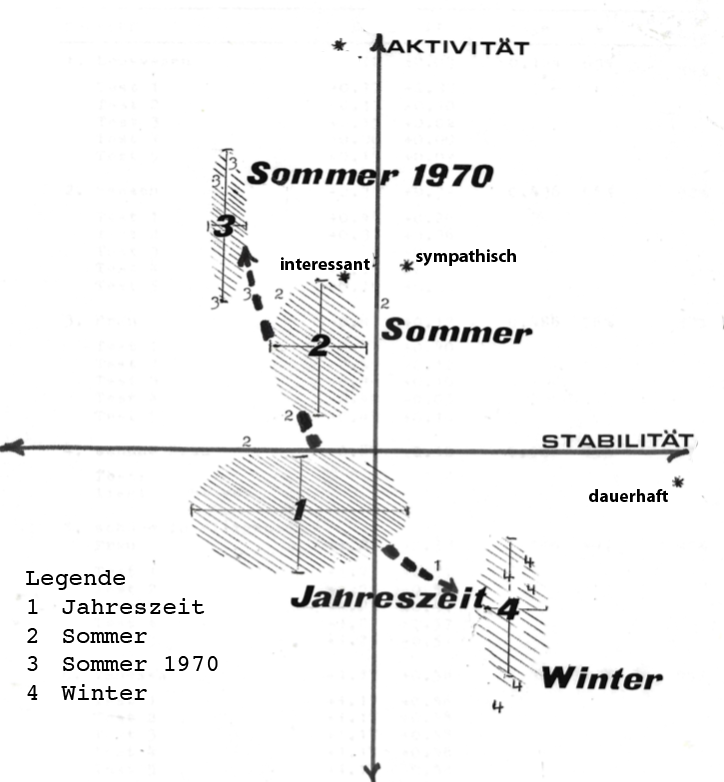
Unschärfe von Bedeutungen in einem Semantischen Raum
Ein weiterer wichtiger Unterschied besteht in der Unschärfe von Bedeutungen. Für uns sind sie nicht dauerhaft präsent, sondern gelangen erst in konkreten Situationen ins Bewusstsein, werden sozusagen situativ in einer realen Welt erzeugt und sind im Wiederholungsfall meist ähnlich, aber nicht identisch.
Selbst das primitive Instrument des Semantischen Differentials reicht aus, um diesen Sachverhalt deutlich zu machen. Die nebenstehende Abbildung zeigt die verschiedenen Orte für die getesteten Begriffe Sommer und Winter in den beiden faktoranalytisch ermittelten Dimensionen Stabilität und Aktivität. Grundlage der Darstellung sind die von einer Person zu verschiedenen Zeitpunkten während eines Monats ausgefüllten Polaritätenprofile. Trotz der zugebbaren Mängel des Testinstruments und -Verfahrens lässt sich aber erkennen, dass es in besagtem Vektorraum eher Bedeutungsfelder als präzise Orte gibt.
Über dieses in den Sprachwissenschaften bekannte Phänomen gibt es mehrere liguistische Theorien. Zum Beispiel geht Leo Weisgerber, Begründer der nach ihm vor rund 100 Jahren benannten Wortfeldtheorie, davon aus, dass die Bedeutung eines Wortes nicht durch seine Einzelbedeutung, sondern durch seine Beziehungen zu anderen Wörtern in einem Wortfeld bestimmt wird. Solche Wörter sind nach ihm durch gemeinsame Merkmale miteinander verbunden, die erst das Wortfeld als Ganzes definieren.
Wenn man versucht, die von Menschen gebildeten Bedeutungen in einem Modell wie dem Semantischen Raum der IT-Sprachmodelle abzubilden, kann man schnell erkennen, dass in unserem Gehirn die Orte solcher Bedeutungen mit der Zeit und der konkreten Situation variieren, also dynamisch gebildet und verändert werden.
Die Semantischen Räume der Language Models dagegen sind statisch. Ist ihr Vokabular einmal trainiert, stellt es ein festes Koordinatensystem im Vektorraum ihres Semantischen Raums dar. Dieser Zustand wird bei den großen Sprachmodellen erst nach Milliarden bis Billionen solcher Trainingsschritte erreicht. Erst beim nächsten Training wird es neu justiert. Im laufenden Betrieb kann das System die Verbindungsgewichte seiner Neuronen nicht selbsttätig, etwa veranlasst durch Benutzeraktivitäten, ändern, sondern nur dann, wenn es dazu von außen veranlasst wird. Das geschieht entweder manuell, also durch Menschen mit einer Art Administrator- oder Supervisionsfunktion, oder in besonderen Fällen durch Fehlererkennungsalgorithmen, die angestoßen werden müssen, beispielsweise bei abgebrochenen Antworten oder bei vom System selbst verschuldeten Inkonsistenzen.
Lernende Systeme?
In der Sprache der Systemanbieter ist immer wieder von Lernenden Systemen die Rede. Das ist jenseits der Werbewirkung dieser Bezeichnung schon richtig, aber betrifft nur die Trainingsphase des Systems. Das Lernen endet mit Abschluss des Trainings.
Ich habe versucht, von Googles Chatbot eine Antwort zu erhalten, ob ein Large Language Model während der Nutzung die Verbindungsgewichte seiner Neuronen verändern kann. Erst nach einer längeren Fragesequenz rückte Gemini (damals noch Bard) mit einem „Nein“ heraus, um allerdings die Antwort gleich wieder zu relativieren. Dass Chatbots durchaus aktuelle Fragen beantworten können, hat mit Lernen wenig zu tun. Sie müssen in kurzen Zeiträumen mit zusätzlichen Daten nachtrainiert werden. Sie haben auch die Möglichkeit, Benutzeranfragen an eine Suchmaschine zu delegieren und das Ergebnis dann als Input für eine sprachliche Aufbereitung oder Zusammenfassung zu benutzen.
Menschen dagegen lernen durch laufendes Erleben und Erfahren. Die Entwicklung des Gehirns ist ein fortlaufender Prozess, der - in unterschiedlichen Phasen und mit unterschiedlicher Heftigkeit - noch im Erwachsenenalter andauert. Die entscheidenden Strukturen sind nicht statisch. Fragt man uns etwas Unbekanntes, so müssen wir unser Gedächtnis sowie unseren sortierenden und ordnenden Verstand bemühen. Wissen wir etwas nicht, so haben wir immer mehrere Möglichkeiten, zum Beispiel:
- tiefer im Gedächtnis zu graben,
- je nach Charakter, Intelligenz, Befindlichkeit oder Laune durch Neugier oder Notwendigkeit getrieben uns auf Entdeckungsreise zu begeben
- oder einfach zuzugeben, nichts zu wissen.
Was immer wir tun, dabei verändert sich unser Gehirn. Nach und schon während einem Lernvorgang oder einer Erfahrung verändern sich die Synapsen in den Verbindungen zwischen den Nervenzellen unseres Gehirns, den Neuronen. Neurowissenschaftler schätzen, dass jedes der rund 100 Milliarden Neurone bis zu 10.000 Verbindungen zu anderen Neuronen haben kann. Das macht dann zwischen 10 und 100 Billionen Synapsen, Stand 2024.
Eine wesentliche Barriere für das Computer-Lernen ist die intrinsische Unfähigkeit der Computer, vergessen zu können. Unsere Fähigkeit des Vergessenkönnens kann man auch als Leistung betrachten, nämlich als Selektion nach Relevanz, Wichtiges behalten, Unwichtiges loswerden. Künstliche Intelligenz braucht eigene Strategien, sich vor dem steigenden Müll-Pegel unwichtiger Informationen zu retten. Aber wir haben ja noch die Hoffnung auf die Quantencomputer mit ihrer tausendfach gesteigerten Rechnerleistung.
Die schlauen Jungs aus dem Silicon Valley machen das schon richtig. Sam Altman hat in Quantencomputer und in Fusionstechnik investiert, das eine für die Rechnerleistung in der Zukunft, das andere um den gigantischen Energiehunger der künftigen KI-Systeme.
Systemgrenzen
In den heute bekannten Large Language Models muss die menschliche „Hardware“ unseres Gehirns komplett in Software simuliert werden. Man müsste Modelle bauen können, die die Anzahl ihrer softwaretechnisch gebildeten Neuronen sowie deren Verbindungen und die Verbindungsgewichte im laufenden Betrieb verändern können, um die Vorgänge im Gehirn nachzubilden.
Das Ende-bei-Null-Spiel: Es kann geschehen, dass Benutzeranforderungen an ein Sprachmodell Wortkombinationen enthalten, die das Modell in seinem Trainingsvokabular nicht findet und auch mit Hilfe seiner tokenisierten Vokabeln nicht bilden kann. Beim Versuch, in einer solchen Situation eine Antwort zu erzeugen, treffen die Systeme dann auf Wahrscheinlichkeiten mit dem Wert Null. Mit Null zu hantieren ist nicht erfreulich, v.a. wenn man damit multiplizieren muss. Alles bleibt dann eben Null, und damit Ende der Fahnenstange.
Um das zu vermeiden, behelfen sich die Systeme mit Tricks. Die Wahrscheinlichkeit, eine bestimmte Wortkombination zu finden, errechnet sich aus der Häufigkeit eben dieser Wortkombination geteilt durch die Größe des gesamten Vokabulars. Das kann schon ein paar Milliarden Einheiten umfassen. Um dieses Ende-bei-Null-Spiel zu durchbrechen, addiert das System einfach eine kleine Zahl zu der Null-Wahrscheinlichkeit und als ausgleichende Gerechtigkeit auch zu der Größe des Vokabulars. Das ist keine große Veränderung, denn die Relationen bleiben ja erhalten: 0 zu 10 Milliarden z.B. ist nicht viel anders als 1 zu 10 Milliarden plus 1. Jetzt entsteht ein neuer, sehr sehr kleiner Wert anstelle der ursprünglichen Null-Wahrscheinlichkeit. Der Vorteil ist, das Spiel kann jetzt weitergehen. Aber die Kehrseite kann sein, dass das System Gefahr läuft zu „halluzinieren“.
Es wurde schon erwähnt, dass die Dynamik der Datenbestände für die großen Sprachmodelle nur darin besteht, ihr „Wissen“ durch zusätzliche Trainings mit neuen Daten zu erweitern oder aktuell zu halten. Für Menschen ist Lernen ein kontinuierlicher Prozess.
Ein weiterer Aspekt ist, dass das „Wissen“ der Systeme zwar einen gigantischen Datenbestand umfasst, aber für alle Nutzungen ein statisches Datenreservoir darstellt. Das „Datenreservoir“ der Menschen dagegen umfasst Wissen und Gefühle, verändert sich stetig und hängt von verschiedenen Faktoren ab, z.B. von Bildung und Interessen.
Mustererkennung und Kreativität
Namhafte Wissenschaftler bescheinigen den Neuronalen Netzen und Sprachmodellen Kreativität und Intuition. Wenn man unter Kreativität versteht, dass solche Systeme Ergebnisse hervorbringen können, die von der bisherigen Erfahrung abweichen, dann kann man dies bestätigen.
Die Stärke der Neuronalen Netze besteht vor allem darin, Muster in Daten zu erkennen und zu lernen, diese Muster zu reproduzieren. Dadurch können neue Texte, Bilder, Musikstücke oder andere Inhalte entstehen, die sich von dem unterscheiden, was wir bisher gesehen oder gehört haben.
Diese Kreativität ist allerdings begrenzt. Sie ist an die Daten gebunden, auf denen das System trainiert wurde. Das bedeutet, sie können nur neue Ideen generieren, die sich aus Kombinationen der Daten des Systemvokabulars herstellen lassen. Der Datenbestand der großen generativen KI-Systeme umfasst zwar gigantische Datenmengen, aber was dort nicht vorkommt, kann auch nicht gefunden werden. Die Systeme sind nicht metaebenenfähig, wenn man unter Metaebene das Verlassen der Dimensionen des bisherigen Denkens verstehen will.
Sie können uns allerdings dabei helfen, unsere Fähigkeit anzukurbeln, in Analogien zu denken und auf der Basis bereits irgendwo vorhandener Informationen Ideen zu entwickeln, auf die wir selbst bisher nie gekommen wären. Damit können sie neue Perspektiven und Möglichkeiten unseres Denkens eröffnen, vorausgesetzt, wir haben gelernt, um die Grenzen der Leistungsfähigkeit solcher Systeme zu wissen.
Es dürfte aber klar sein, dass wir mit der heutigen KI-Technik weit entfernt sind von den Phantasien über eine Superintelligenz, die ihre Algorithmen und Strukturen selbständig verbessern und die Kontrolle über die Menschheit übernehmen kann.
 |
Karl Schmitz | Februar 2024 Update Juni 2024 |
 tse Hamburg
tse Hamburg |
553 / 589 |